java注解
注解
什么是注解
注释会被编译器直接忽略,注解则可以被编译器打包进入class文件,因此,注解是一种用作标注的“元数据”。
从JVM的角度看,注解本身对代码逻辑没有任何影响,如何使用注解完全由工具决定。
Java的注解可以分为三类:
第一类是由编译器使用的注解,例如:
@Override:让编译器检查该方法是否正确地实现了覆写;@SuppressWarnings:告诉编译器忽略此处代码产生的警告。
这类注解不会被编译进入.class文件,它们在编译后就被编译器扔掉了。
如lombox插件使用的是 JDK 6 实现的 JSR 269: Pluggable Annotation Processing API (编译期的注解处理器) ,它是在编译期时把 Lombok 的注解代码,转换为常规的 Java 方法而实现优雅地编程的。
第二类是由工具处理.class文件使用的注解,比如有些工具会在加载class的时候,对class做动态修改,实现一些特殊的功能。这类注解会被编译进入.class文件,但加载结束后并不会存在于内存中。这类注解只被一些底层库使用,一般我们不必自己处理。
第三类是在程序运行期能够读取的注解,它们在加载后一直存在于JVM中,这也是最常用的注解。例如,一个配置了@PostConstruct的方法会在调用构造方法后自动被调用(这是Java代码读取该注解实现的功能,JVM并不会识别该注解)。
定义一个注解
Java语言使用@interface语法来定义注解(Annotation),它的格式如下:
public @interface Report {
int type() default 0;
String level() default "info";
String value() default "";
}注解的参数类似无参数方法,可以用default设定一个默认值(强烈推荐)。最常用的参数应当命名为value。
元注解
有一些注解可以修饰其他注解,这些注解就称为元注解(meta annotation)。Java标准库已经定义了一些元注解,我们只需要使用元注解,通常不需要自己去编写元注解。
@Target
最常用的元注解是@Target。使用@Target可以定义Annotation能够被应用于源码的哪些位置:
- 类或接口:
ElementType.TYPE; - 字段:
ElementType.FIELD; - 方法:
ElementType.METHOD; - 构造方法:
ElementType.CONSTRUCTOR; - 方法参数:
ElementType.PARAMETER。
例如,定义注解@Report可用在方法上,我们必须添加一个@Target(ElementType.METHOD):
@Target(ElementType.METHOD)
public @interface Report {
int type() default 0;
String level() default "info";
String value() default "";
}定义注解@Report可用在方法或字段上,可以把@Target注解参数变为数组{ ElementType.METHOD, ElementType.FIELD }:
@Target({
ElementType.METHOD,
ElementType.FIELD
})
public @interface Report {
...
}实际上@Target定义的value是ElementType[]数组,只有一个元素时,可以省略数组的写法。
@Retention
另一个重要的元注解@Retention定义了Annotation的生命周期:
- 仅编译期:
RetentionPolicy.SOURCE; - 仅class文件:
RetentionPolicy.CLASS; - 运行期:
RetentionPolicy.RUNTIME。
如果@Retention不存在,则该Annotation默认为CLASS。因为通常我们自定义的Annotation都是RUNTIME,所以,务必要加上@Retention(RetentionPolicy.RUNTIME)这个元注解:
@Retention(RetentionPolicy.RUNTIME)
public @interface Report {
int type() default 0;
String level() default "info";
String value() default "";
}@Repeatable
使用@Repeatable这个元注解可以定义Annotation是否可重复。这个注解应用不是特别广泛。
@Repeatable(Reports.class)
@Target(ElementType.TYPE)
public @interface Report {
int type() default 0;
String level() default "info";
String value() default "";
}
@Target(ElementType.TYPE)
public @interface Reports {
Report[] value();
}经过@Repeatable修饰后,在某个类型声明处,就可以添加多个@Report注解:
@Report(type=1, level="debug")
@Report(type=2, level="warning")
public class Hello {
}@Inherited
使用@Inherited定义子类是否可继承父类定义的Annotation。@Inherited仅针对@Target(ElementType.TYPE)类型的annotation有效,并且仅针对class的继承,对interface的继承无效:
@Inherited
@Target(ElementType.TYPE)
public @interface Report {
int type() default 0;
String level() default "info";
String value() default "";
}在使用的时候,如果一个类用到了@Report:
@Report(type=1)
public class Person {
}则它的子类默认也定义了该注解:
public class Student extends Person {
}如何定义Annotation
我们总结一下定义Annotation的步骤:
第一步,用@interface定义注解:
public @interface Report {
}第二步,添加参数、默认值:
public @interface Report {
int type() default 0;
String level() default "info";
String value() default "";
}把最常用的参数定义为value(),推荐所有参数都尽量设置默认值。
第三步,用元注解配置注解:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface Report {
int type() default 0;
String level() default "info";
String value() default "";
}其中,必须设置@Target和@Retention,@Retention一般设置为RUNTIME,因为我们自定义的注解通常要求在运行期读取。一般情况下,不必写@Inherited和@Repeatable。
注解定义后也是一种class,所有的注解都继承自java.lang.annotation.Annotation,因此,读取注解,需要使用反射API。
ioc
Spring提供的容器又称为IoC容器,什么是IoC?
IoC全称Inversion of Control,直译为控制反转。
因此,IoC又称为依赖注入(DI:Dependency Injection),它解决了一个最主要的问题:将组件的创建+配置与组件的使用相分离,并且,由IoC容器负责管理组件的生命周期。
<beans>
<bean id="dataSource" class="HikariDataSource" />
<bean id="bookService" class="BookService">
<property name="dataSource" ref="dataSource" />
</bean>
<bean id="userService" class="UserService">
<property name="dataSource" ref="dataSource" />
</bean>
</beans>Spring的IoC容器同时支持属性注入和构造方法注入,并允许混合使用。还支持接口注入
@Component注解打在类上,表明是让ioc容器管理,自动创建bean
@Bean 打在@Configuration的类中方法上用于引入第三方组件。
@Autowired注解打在接口上,Spring会按类型寻找接口的实现类,将其注入。存在多个实现类,应该指定名字,可以通过 byName 注入的方式。可以使用 @Resource 或 @Qualifier 注解。 注意:static静态变量无法直接注入
aop切面
aop(Aspect-oriented programming)
切面,即一个横跨多个核心逻辑的功能,或者称之为系统关注点;如日志,权限
@aspect
实际使用时,一般自定义一个注解,打在连接点的方法上
@Aspect
@Component
public class MetricAspect {
//注意第二个参数必须为注解
@Around("@annotation(metricTime)")
public Object metric(ProceedingJoinPoint joinPoint, MetricTime metricTime) throws Throwable {
String name = metricTime.value();
long start = System.currentTimeMillis();
try {
return joinPoint.proceed();
} finally {
long t = System.currentTimeMillis() - start;
// 写入日志或发送至JMX:
System.err.println("[Metrics] " + name + ": " + t + "ms");
}
}
}拦截器类型
顾名思义,拦截器有以下类型:
- @Before:这种拦截器先执行拦截代码,再执行目标代码。如果拦截器抛异常,那么目标代码就不执行了;
- @After:这种拦截器先执行目标代码,再执行拦截器代码。无论目标代码是否抛异常,拦截器代码都会执行;
- @AfterReturning:和@After不同的是,只有当目标代码正常返回时,才执行拦截器代码;
- @AfterThrowing:和@After不同的是,只有当目标代码抛出了异常时,才执行拦截器代码;
- @Around:能完全控制目标代码是否执行,并可以在执行前后、抛异常后执行任意拦截代码,可以说是包含了上面所有功能。
Springboot
Spring Boot自动装配功能是通过自动扫描+条件装配实现的,这一套机制在默认情况下工作得很好,但是,如果我们要手动控制某个Bean的创建,就需要详细地了解Spring Boot自动创建的原理,很多时候还要跟踪XxxAutoConfiguration,以便设定条件使得某个Bean不会被自动创建。
谈一下对spring的理解
ioc,aop
spring源码
spring是什么?
是个框架,狭义的讲是个容器。具体是ApplicationContext继承自BeanFactory接口,这个容器装的叫bean,bean是一个被实例化,组装,并通过Spring IoC 容器所管理的java对象。具体点就是JVM管理对象,我们又自己把对象包装一下,放到框架里。
好我们现在有了一个容器管理各种对象,那么如果向容器中添加一个处理http请求的对象。
用开发 web 应用( SpringMVC )。然后有发现每次开发都写很多样板代码,为了简化工作流程,于是开发出了一些“懒人整合包”(starter),这套就是 Spring Boot。
管理bean,是spring最核心的作用,因此我将以bean的生命周期为主线,详细展开解释
Spring何时初始化bean
- singleton:单实例的(默认值)
默认情况下,Bean是单例的,会在容器(也就是ApplicationContext)创建时就实例化,在后续getBean()时(也就是使用的时候)不再创建新的实例,因为是单例的。也可以通过 XML 文件中 bean 标签的 lazy-init 属性或 @Lazy 注解将其设置为懒加载模式,也就是在容器创建时不实例化对象,而是第一次getBean()的时候才实例化。 - prototype:多实例的
这种模式下的 Bean 是多实例的,也就是可以创建多个对象,在容器创建时不会实例化Bean,而是在每一次getBean()时都会创建一个新的实例。
bean的生命周期
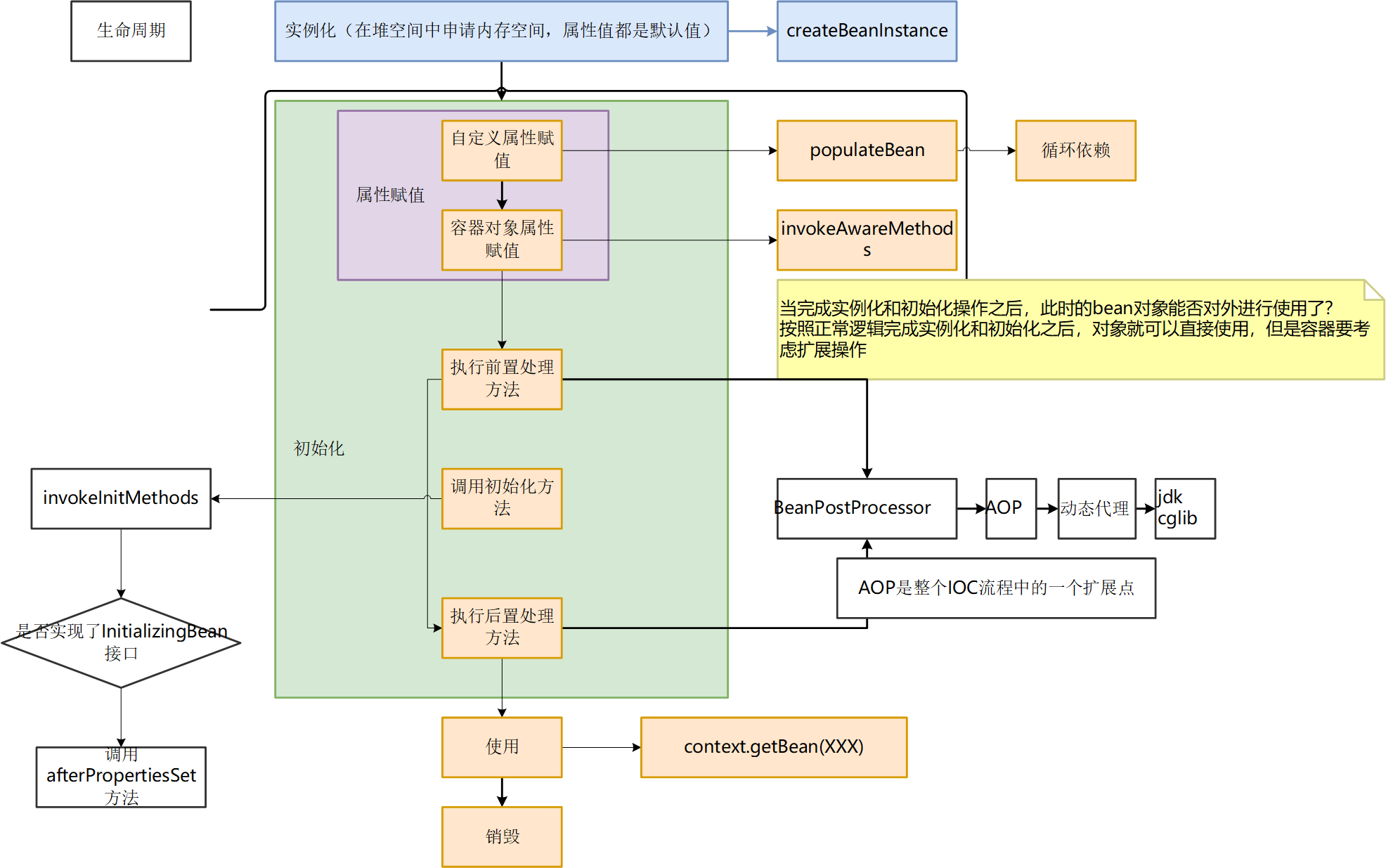
实例化bean对象(分配内存)
根据什么来实例化bean呢?他的定义是什么?不是像java类那样,直接代码里一定义,然后根据定义实例化。而是通过先通过xml文件(spring),或者注解(springboot)来定义
//applicationContext.xml文件
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource">
<property name="username" value="${jdbc.username}"></property>
<property name="password" value="${jdbc.password}"></property>
<property name="url" value="${jdbc.url}"></property>
<property name="driverClassName" value="${jdbc.driverClassName}"></property>
</bean>比方说xml文件,先打开文件用io流读入到内存中,然后使用xml文档解析器如sax或者dom4j解析得到document对象,然后就可以在程序中遍历node,得到key value对,最终封装成beandefinition对象

然后直接根据BeanDefinition去实例化一个bean对象?
并不是,而是还要经过BeanFactoryPostProcessor处理,处理前 dollar $的value并未指定,需要去修改容器里的BD对象,将BeanFactoryPostProcessor中的value替换为实际值。当然我们也可以自己实现这个接口。
此时,才可以去实例化bean对象,具体是createBeanInstance方法。
(拓展,这里面蕴含了一种设计模式,叫什么??)
说到这里,spring的魅力已经开始体现了,拓展性很强,已经给了我们两个拓展点,怎么读,怎么替换属性。
上述规范由BeanDefinitionReader接口定义,然后有多种实现类,比方上面读xml文件的XmlBeanDefinitionReader。我们也可以自定义自己的实现类,极大的提高了spring框架的拓展性
(拓展)接口与抽象类,自上向下(不用考虑实现),自下向上(从子类中抽象出公共的特性形成抽象类)
(拓展,两种增强器)
一种beanFactory postProcessor,前置处理器,刚提过
这个机制允许我们在实例化相应对象之前对注册到容器中的BeanDefinition的存储信息进行修改。可以根据这个机制对Bean增加其它信息。修改Bean定义的某些属性值。
想自定义前置处理器需要实现BeanFactoryPostProcess接口。当一个容器存在多种前置处理的时候,可以让前置处理器的实现类同时继承Ordered接口。
Spring容器提供了数种现成的前置处理器,常见的如:
PropertyPlaceholderConfigurer:允许在xml文件中使用占位符。将占位符代表的资源单独配置到简单的Properties文件中加载
PropertyOverrideConfigurer:不同于PropertyPlaceholderConfigurer的是,该类用于处理容器中的默认值覆为新值的场景
CustomEditorConfigurer:此前的两个前置处理器处理的均是BeanDefinition.通过把BeanDefinition的数据修改达到目的。CustomEditorConfigurer没有对BeanDefinition做任何变动。负责的是将后期会用到的信息注册到容器之中。例如将类型转换器注册到BeanDefinition中。供BeanDefinition将获取到的String类型参数转换为需要的类型。
另一种后置处理器 bean postProcessor,在接下来初始化中会用到,包括两个方法
实例后的对象,初始化之前BeanBeforePostProcessor
实例后的对象,初始化之后BeanAfterPostProcessor

(拓展,BeanFactoryPostProcessor怎么替换BeanDefinition中的value,用反射)
1、获取Class对象
Class clazz = Class.forName("完全限定名")
Class clazz = 类名.class;
Class clazz = 对象名.getClass();
2、获取构造器对象
Constructor ctor = clazz.getDeclaredConstructor();//默认无参,如果要有参则传入参数的Class。也可以不用构造器,直接clazz.newInstance()默认无参
Declared是指包括public的和非public的,当然也包括private的构造器。
3、创建对象
Object obj = ctor.newInstance();
初始化(6个步骤)
怎么初始化呢?
属性赋值
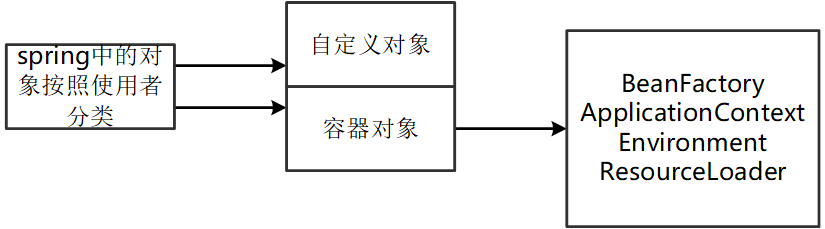
要分为两类进行赋值,自定义对象和容器对象.
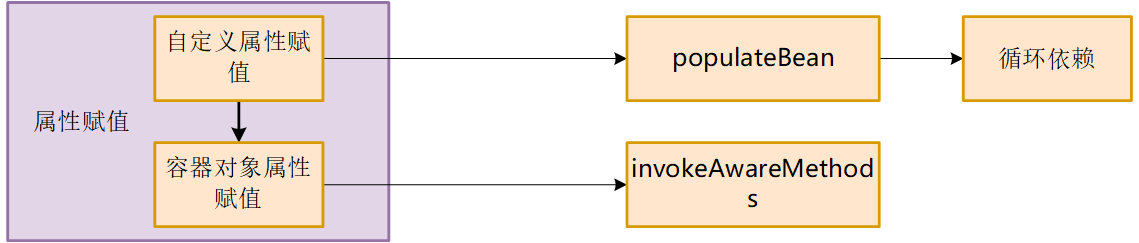
自定义对象属性需要经过8个方法,同时还要使用三级缓存解决循环依赖问题

容器对象属性,赋值通过invokeAwareMethods方法来注入 Aware 接口,会检测该对象是否实现了xxxAware接口,并将相关的xxx实例注入给 Bean。xxx是某个spring底层组件,如BeanFactoryAware,ApplicationContextAware。
注意,Spring 根据BeanDefinition中的信息进行依赖注入,并且通过BeanWrapper提供的设置属性的接口完成依赖注入。从而避免了使用反射机制设置属性。
(拓展,Aware是什么?)
Aware接口,里面啥也没有,BeanFactoryAware接口继承他,统一赋值容器对象属性
使得用户只要实现了Aware子接口的Bean都能获取到一个Spring底层组件。
如BeanFactoryAware、EnvironmentAware、ResourceLoaderAware、ImportAware、BeanNameAware、ApplicationContextAware。
实现XXXAware接口的Bean,那么通过实现的setXXX方法就可以获取到XXX组件对象
包含void setXX(XX 类型的对象)方法,参数是想要获取的Spring组件,spring会在属性赋值时回调这个方法,将对象传入。
(拓展)BeanFactory和ApplicationContext区别
ApplicationContext接口作为BeanFactory的派生。
BeanFactory和ApplicationContext都支持BeanPostProcessor、BeanFactoryPostProcessor的使用,但两者之间的区别是:BeanFactory需要手动注册,而ApplicationContext则是自动注册。
继承MessageSource,因此支持国际化
(拓展)实例化和初始化之后能否直接用?
按照正常逻辑完成实例化和初始化之后,对象就可以直接使用,但是容器要考虑扩展操作
执行前置处理方法,调用初始化方法,执行后置处理方法
实现BeanPostProcessor接口(后置处理器)。有两个方法需要重写。
BeanBeforePostProcessor
BeanAfterPostProcessor
实现InitializingBean接口,需要重写afterPropertiesSet方法。
protected void invokeInitMethods(String beanName, final Object bean, RootBeanDefinition mbd)
{
//判断是否实现了InitializingBean接口
boolean isInitializingBean = (bean instanceof InitializingBean);
//调用afterPropertiesSet方法执行自定义初始化流程
((InitializingBean) bean).afterPropertiesSet();
}

(拓展,aop与ioc的关系)aop是整个ioc流程中的一个扩展点
注册必要的Destruction相关回调接口
用于销毁时使用
使用
可以通过context.getBean(XXX)方法获取
(拓展,beanfactory与applicationContext区别)
beanfactory是个根接口
applicationContext也是一个接口,继承自BeanFactory,接口可以多继承接口
销毁(2个步骤)
检查是否实现DisposableBean接口 和 是否配置自定义的destroy方法
如果 Bean 实现了DispostbleBean接口,Spring 将调用它的destory方法,作用与在配置文件中对 Bean 使用destory-method属性的作用一样,都是在 Bean 实例销毁前执行的方法。
BeanFactory与FactoryBean区别

简单说,一个是流水线,一个是私人订制。
BeanFactory实际上是个根接口,是容器本身。他可以创建对象,但需要经过上述完整的生命周期,比较麻烦。
FactoryBean是实现了FactoryBean接口的Bean。需要实现三个方法,来自己定制要的实例。和config类中的@Bean注解效果类似。注意,实际上这也是spring如何将第三方的类纳入管理。
getBean方法获取的实际上是FactoryBean中getObject()方法返回的实例对象,而并不是直接FactoryBean本身,想要获取FactoryBean对象本身,可以在Bean名前面加一个&符号来获取。
循环依赖
https://zhuanlan.zhihu.com/p/157314153
为什么会产生
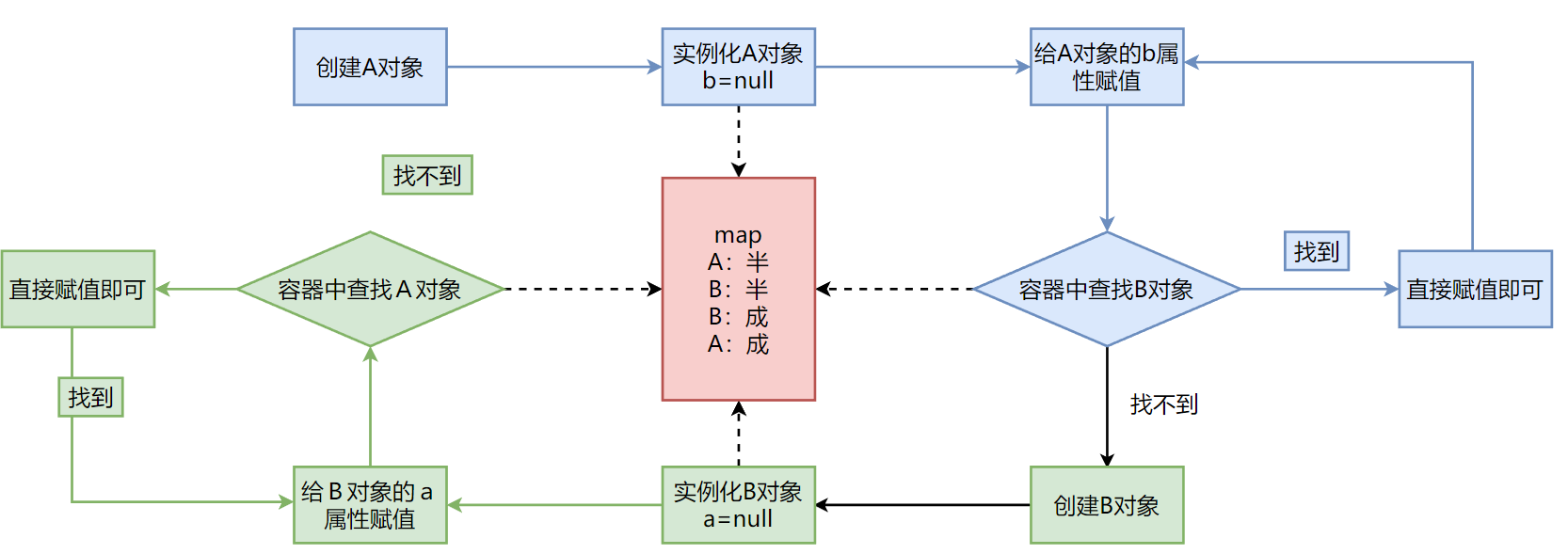
如何解决
思路:如果持有了某一个对象的引用,能否在后续步骤中对该对象进行赋值操作?能
根本解决方法是:将实例化和初始化的步骤完全独立开,允许使用半成品对象
spring的对象创建流程
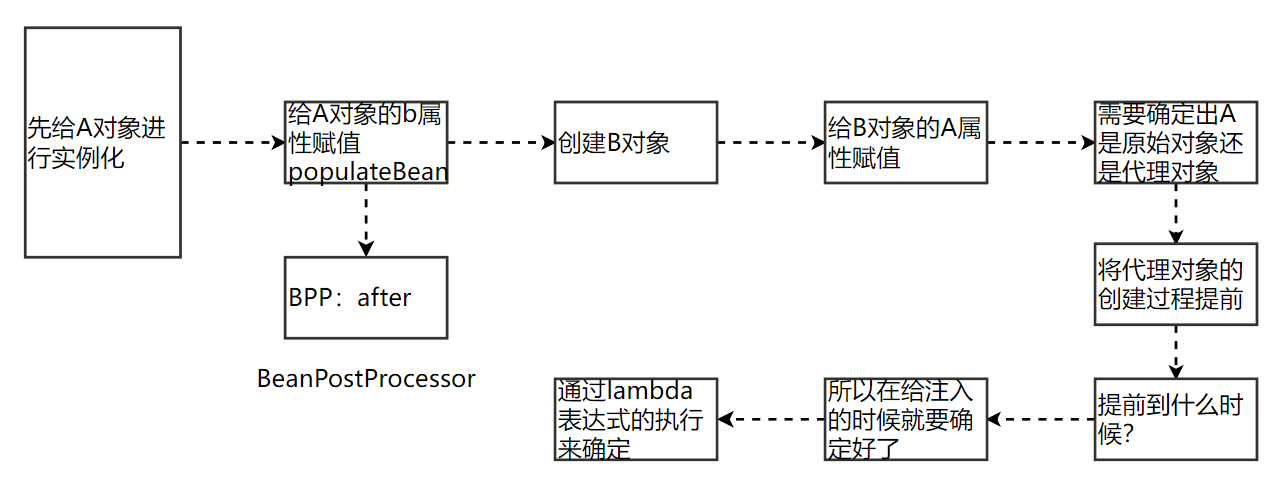
createBeanInstance生成半成品a对象后得到RuntimeBeanReference实例,之后没有立刻放入二级缓存,而是以k:a v:lambda的形式,放入三级缓存,放的是lambda表达式而不是对象
populateBean 填充a属性时,需要创建b对象,得到RuntimeBeanReference实例,同样放入三级缓存,然后populateBean 填充b的属性,此时需要找a对象,也是第二次找a对象时,从一二三级缓存中找,最终在三级缓存中找到,然后执行
三级缓存中的lambda表达式,返回原始对象/代理对象。如果是代理对象,会覆盖原有对象
拿到了半成品的a,此时才把a加到二级缓存中,把三级缓存删掉。
并且用半成品的a给b属性赋值后,这样B对象就变成成品。之后调用addSingleton添加到一级缓存,把二三级删掉
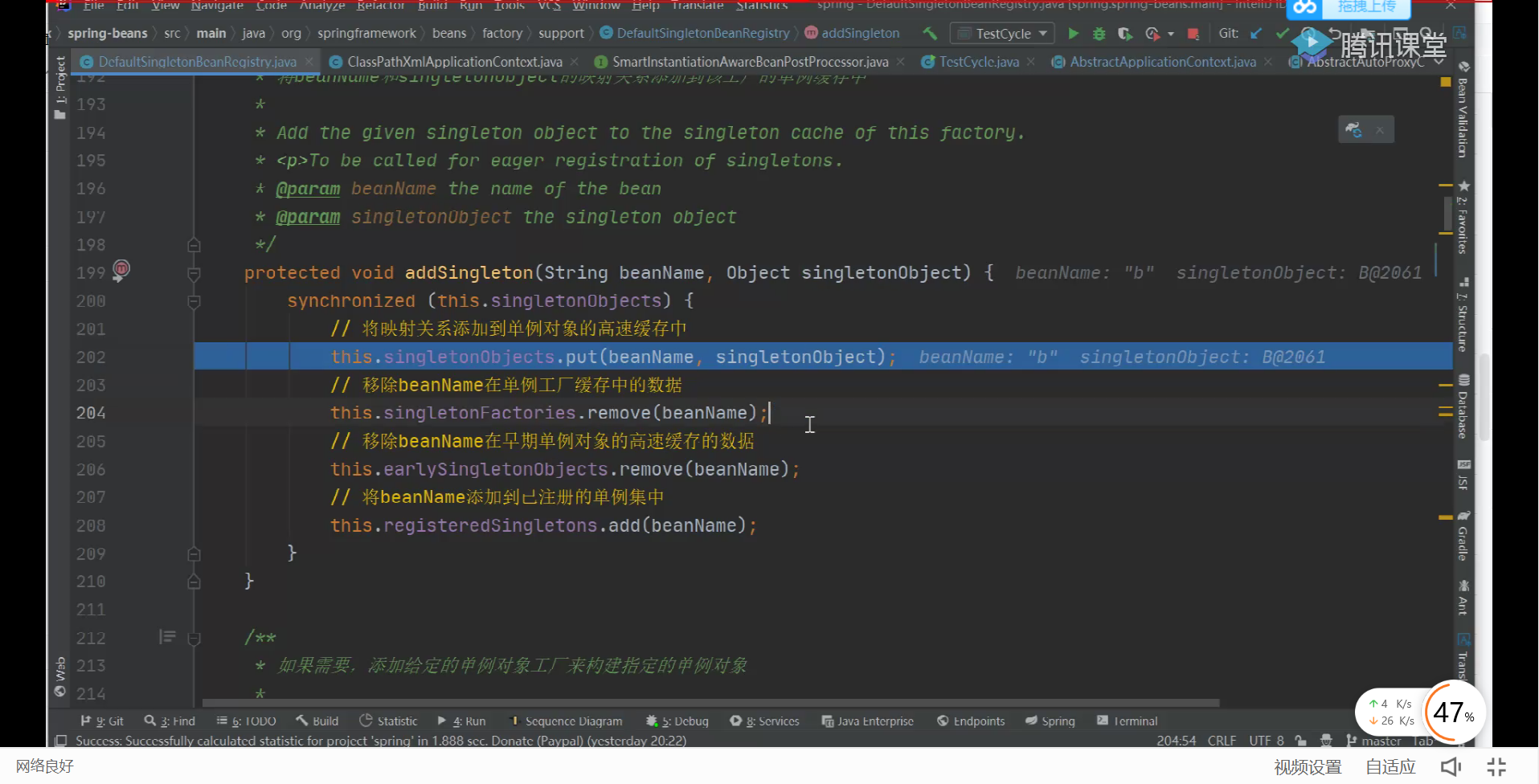
这样A也可以赋值,变成品,调用addSingleton添加到一级缓存,把二三级删掉。
然后尝试创建B,发现b已经在一级缓存,直接返回。
三个map结构分别存放什么对象?
一级缓存:成品
二级缓存:半成品
三级缓存:lambda,实际上一个操作
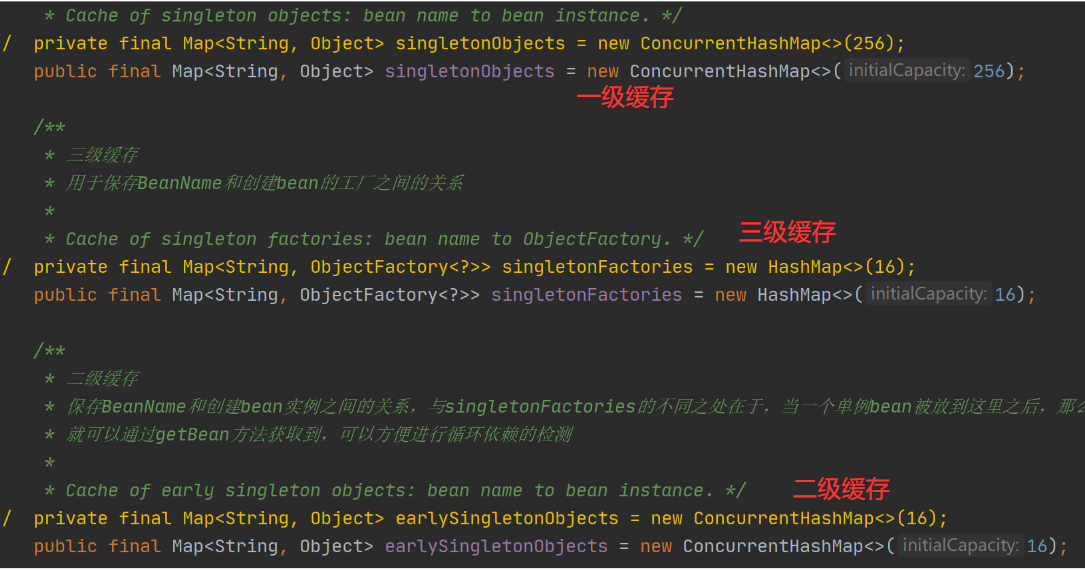

三个map结构的查找顺序?
先查找一级缓存,找不到再找二级缓存,再找不到的话找三级缓存
如果只有一个map缓存,能解决循环依赖问题吗?
理论上是可行的,但是代码不优雅,如果一级缓存中同时放成品和半成品对象,就意味着要通过一个状态标志来区分,可以在value中设置不同的标志位,但是每次在获取对象的时候都要把value取出来,然后判断这个标志位,太麻烦了,直接用两个map就可以很轻松的解决这个问题,如果不做区分,就会存在半成品对象直接对外暴露使用,那么一定会报空指针异常
如果只有两个map缓存,能解决循环依赖问题吗?
可以,但是有前提条件:循环依赖的对象中没有代理对象。有了代理对象,就需要一个操作将原始对象替换为代理对象。从软件设计角度考虑,根据单一职责原理,这个操作是个新的单一职责,就需分离第三种职责的缓存,所以形成三级缓存的状态。
使用了两组三级缓存(放:doCreateBean,取:getSingleton)
为什么必须要使用三级缓存来解决循环依赖问题?
《1》同一个容器中能存在同名的不同的两个对象吗?
不能
《2》创建代理对象的时候是否需要原始对象?
需要
《3》当创建完原始对象之后,紧跟着创建了代理对象,那么对象在引用的时候用哪个?
理论上来说应该是用代理对象的,但是程序是死的,他怎么去判断哪个是代理对象哪个是原始对象呢?不能判断,所以当创建代理对象之后要将代理对象去覆盖原始对象(getEarlyBeanReference)
准确的说是不能根据创建出来的实例对象判断吧????
如果只用两级缓存,启用aop,会报this means that said other bean do not use the final version of the bean
《4》为什么三级缓存需要使用ObjectFactory类型的三级缓存呢?
getEarlyBeanReference是在lambda表达式里进行调用的,为什么要使用lambda表达式呢?
() -> getEarlyBeanReference(beanName, mbd, bean)
ObjectFactory是一个函数式接口,java中方法参数的传递都是值传递,在1.8版本之后,可以将一个lambda表达式作为参数传递到方法中,在方法调用的时候并不会实际的执行此lambda表达式,而是要在方法中调用getObject方法的时候才会去执行lambda表达式。
简单说,我们需要一个操作,只要执行完就能定性对象,而lambda表达式就是这个操作
因为对象的属性赋值和调用是由容器来控制的,我们没有办法判断出什么时候会进行属性的赋值操作,因为在需要对属性赋值的时候必须要唯一的确定出注入的对象是代理对象还是原始对象,正常情况下,代理对象的创建是要在populateBean方法之后完成的(BeanPostProcessor的后置处理方法里面),而属性赋值是在之前执行的,所以要将代理对象的创建工作提前,提前到对象需要被注入的时候,必须要确定好是原始对象还是代理对象,使用lambda表示式类似于一种回调机制,在需要的时候直接定性为代理对象还是原始对象
这个工厂的目的在于延迟对实例化阶段生成的对象的代理,只有真正发生循环依赖的时候,才去提前生成代理对象,否则只会创建一个工厂并将其放入到三级缓存中,但是不会去通过这个工厂去真正创建对象
三级缓存是如何解决循环依赖问题的?
三个map+对象创建流程
生态
前面说过@Bean注解,可以将第三方组件纳入spring项目。
概述
做Java开发的人一提起Spring,首先在脑海中浮现出的就是“IoC”,“AOP”,“Spring MVC”,“Spring Security”等等这些名词,甚至大有“无Spring不Java”的感慨。
实际上,时至今日Spring已不再是一个简单的编程框架了,从最初的“SSH框架”发展到今天,Struts和Hibernate都几乎快要从程序员视野中消失了,而Spring却发展成了一个非常庞大且完整的生态。
所以说,除非特别指明是Spring生态中的某个具体框架,否则提起“Spring”应该指的是整个Spring生态。
说句不夸张的话,Java程序员只要精通了Spring,也就掌握了Java开发的精髓。
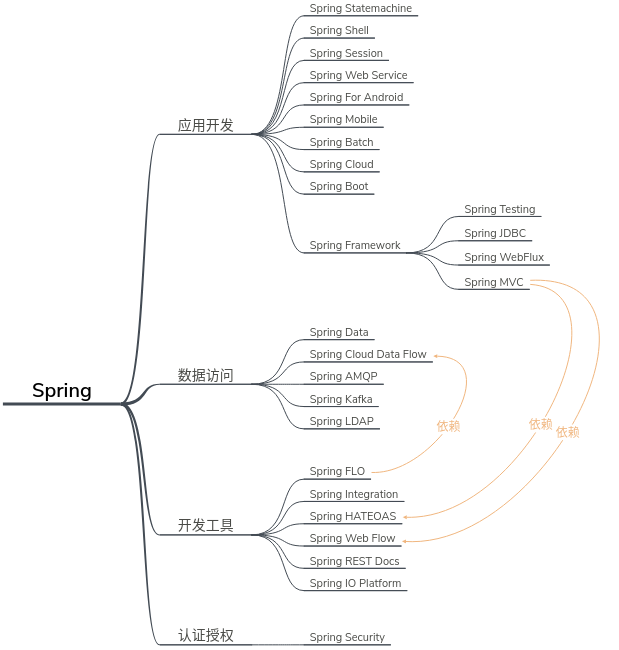
在整个Spring生态中包含了许多应用在特定场景的具体框架,如:“Spring Framework”,“Spring Security”,“Spring Boot”,“Spring Cloud”等等,其中“Spring Framework”框架是整个生态的核心基础,其他框架都需要依赖“Spring Framework”提供的基础功能,而且每个框架都有自己独立的代码仓库。
项目说明
Spring生态下的项目分为3类:主要项目(Main Projects),社区项目(Community Projects),已经终止但是目前还保留的项目(Projects in the Attic)。
最新的Spring生态项目列表详见:https://spring.io/projects 。
主要项目
目前,Spring生态中包含22个主要活跃的项目。

1.Spring Framework
Spring Framework项目是整个Spring生态的基础,包含了Spring最核心的功能,如:IoC,AOP,Spring MVC等,其他项目都需要依赖Spring Framework。
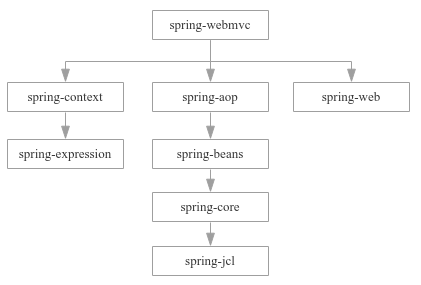
另外,还需要注意的是Spring Framework项目又包含多个子模块,如:spring-core,spring-beans,spring-context,spring-aop,spring-web,spring-webmvc等等。实际上,Spring Framework项目是一个模块化的架构,各模块之间又存在依赖关系。我们在Java Web后台项目中使用得最多的Spring MVC实际上就是模块spring-webmvc,它与其他模块的依赖关系如下所示:
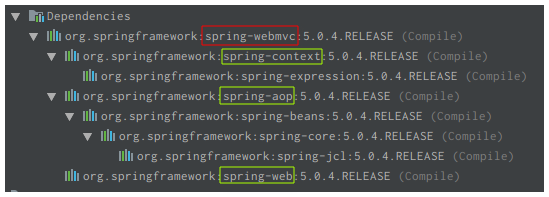
显然,spring-webmvc模块依赖spring-context,spring-aop和spring-web。
2.Spring Boot
Spring Boot是一个开发基于Spring的脚手架项目,它默认集成了嵌入式Tomcat,配置注解化,支持快速集成第三方开发组件(如MyBatis),大大降低了使用Spring的门槛,而且内置了许多可以直接用于生产环境的功能,是目前用于开发微服务架构项目的不二选择。
值得注意的是: 许多人刚接触Spring Boot的人把它神话了,固然使用Spring Boot能快速开发一个健壮的、可直接运行的项目,但是它的核心和基础来源于Spring Framework。对于重度依赖Spring的开发人员,应该先去吃透Spring Framework,只要真正掌握了Spring Framework中各个模块的实现原理,对于在实际开发中使用Spring Boot遇到的问题也就迎刃而解了。
3.Spring Cloud
Spring Cloud为开发基于微服务架构的软件系统提供了一整套工具集合,其中包含了开发各个微服务组件的具体项目,如:Spring Cloud Config(配置中心),Spring Cloud Netflix(服务注册中心),Spring Cloud Sleuth(服务调用监控),Spring Cloud Gateway(服务网关)等等。
Spring Cloud的基础是Spring Boot,基于Spring Boot可以大大简化开发各微服务组件的流程。
4.Spring Cloud Data Flow
Spring Cloud Data Flow用于构建在云环境或K8S中基于微服务的实时或批数据处理架构,具体来讲就是支持一系列需要进行数据处理的场景,如:ETL,数据导入/导出,事件流,预测分析等等。
5.Spring Data
Spring Data旨在提供一套基于Spring编程模型的数据访问API,是一个数据访问框架集合,其中包含了多个具体的支持不同方式访问特定数据库类型的子模块,如:Spring Data JDBC(使用JDBC方式访问关系型数据库),Spring Data MongoDB(访问MongoDB数据库)等。
这个模块的功能类似于MyBatis这样的专门的ORM框架,在实际开发中可以根据需求进行灵活选择。
6.Spring Integration
Spring Integration的目的是提供一个简单的模型,用于构建企业级应用集成解决方案。
7.Spring Batch
Spring Batch是一个轻量级的批处理框架,旨在开发对企业系统日常运营至关重要的强大批处理应用程序。
支持事务管理,提供了基于Web的管理接口。
8.Spring Security
Spring Security是用于实现认证和授权,以及访问控制的安全框架,在Java生态与之提供类似的功能还有一个框架:Apache Shiro。
Spring Security依赖于Spring Framework,也就是说如果要Spring Security,那么应用架构也必须是基于Spring Framework的,这大大限制了Spring Security的使用场景;反之,Shiro就没有这样限制,而且从项目架构上Shiro更加简洁。当然,Spring Security提供了非常丰富的安全控制的功能,在某些方面甚至比Shiro更加完善,与之对应的是掌握的Spring Security的复杂度比较大。因此,对于在应用中是否选择Spring Security需要根据实际需求来决定。
9.Spring HATEOAS
如果Web应用基于Spring框架(即:使用了Spring MVC)开发,那么可以直接使用Spring HATEOAS来开发满足HATEOAS约束的RESTFul服务。
这里需要理解一个单词简写:“HATEOAS”。HATEOAS(Hypermedia as the engine of application state)是REST架构风格中最复杂的约束,也是构建成熟REST服务的核心。它的重要性在于打破了客户端和服务器之间严格的契约,使得客户端可以更加智能和自适应,而 REST 服务本身的演化和更新也变得更加容易。
10.Spring REST Docs
Spring REST Docs是一个文档工具,用于为REST架构风格的Web服务自动生成相应的文档,这样可以解放开发者专门撰写API文档的工作。
11.Spring AMQP
Spring AMQP项目旨在将核心的Spring概念应用于基于AMQP的消息传递解决方案的开发中,它提供了一个“模板”的抽象用于发送和接收消息。
12.Spring Mobile
Spring Mobile是对Spring MVC的扩展,旨在简化移动Web应用的开发。
Spring Mobile可以检测出当前请求使用的设备是PC、还是手机或者是平板以及用户设备是安卓平台还是iOS平台,然后根据请求设备的不同,返回适合该设备的视图。
13.Spring For Android
虽然官方的说法是Spring For Android旨在简化原声Android应用的开发,但其实这个有点太过于牵强。
Spring For Android提供了2个对原生Android应用开发的支持:
(1)提供了一个REST客户端
(2)支持访问安全API时的认证
14.Spring Web Flow
Spring Web Flow主要应用于需要在Web页面上创建引导用户执行类似“下一步”这样的基于流程的应用场景,该框架构建于Spring MVC之上。
15.Spring Web Services
Spring Web Services用于开发WebService服务,类似的框架如:Apache CXF,Apache Axis2。
16.Spring LDAP
Spring LDAP是一个工具,用于为基于Spring的应用程序使用LDAP(Lightweight Directory Access Protocol)协议。
17.Spring Session
Spring Session提供了管理用户Session信息的API和对应实现,Spring Session使得支持集群会话变得简单,而不依赖于特定于应用程序容器的解决方案。
简单来讲,传统的Session方案依赖于特定的容器(如:Tomcat),Spring Session就是提供独立于特定容器的Session解决方案。
其实,针对Tomcat容器,Session集群化也有一个开源方案:tomcat-redis-session-manager。
18.Spring Shell
Spring Shell用于开发基于命令行交互的应用。
19.Spring FLO
Spring FLO是一个JavaScript类库,是Spring Cloud Data Flow中流构建器的基础。
20.Spring Kafka
Spring Kafka用于在Spring项目中与Kafka交互。
21.Spring Statemachine
Spring Statemachine是一个为开发人员在Spring项目中使用状态机的框架,帮助开发者简化状态机的开发过程,让状态机结构更加层次化。
22.Spring IO Platform
简单来说,Spring IO Platform是一个对项目依赖进行统一版本管理的工具。本质就是一个pom文件,它记录了Spring项目和其它第三方库对应的版本信息。
社区项目
社区项目目前只有2个:Spring ROO,Spring Scala。
1.Spring ROO:这是一个开发工具包,旨在快速构建一个Java应用。
2.Spring Scala:支持在Scala中使用Spring框架。
保留项目
某些项目已经终止了,但是仍然保留着,不必赘述。
最后总结
Spring是一个生态系统,提供许多有用的编程框架或工具集。
本文的目的不在于详细介绍Spring生态的每一个项目,而是通过一个全面的整理,对Spring生态有一个完整的认识,在实际中根据需要灵活选择对应的组件来使用即可。
可以明确的是,当下最为流行的Spring项目是这4个:Spring Framework,Spring Security,Spring Boot,Spring Cloud。
如下图所示,再次对Spring生态做一个概括性总结。
学习源码方法论
不要忽略注释,先梳理脉络,再去扣细节,见名知意,大胆猜测,小心验证,善于使用小工具,translate,sequenceDiagram,坚持坚持再坚持
融会贯通
springboot
如何创建一个springboot项目
1官网
一样的
2idea直接创建
3idea maven archetype原型 org.springframework.boot
springboot缺点是什么,为什么要用springcloud?
单体架构,一体化架构,会有性能瓶颈
分布式微服务架构springcloud解决方案
springboot是什么
本质,在SpringFramework(IOC )基础上进行再 封装的的一个上层应用,作用,简化开发
@Bean注解的方法,返回的new 对象,经过bean的生命周期吗?
(拓展,约定优于配置)
是一种软件设计的范式。
简单来说,就是你所使用的工具默认会提供一种约定,如果这个约定和你的期待相符合,就可以省略那些基础的配置,否则,你就需要通过相关配置来达到你所期待的方式。
举个例子,比如交通信号灯,红灯停、绿灯行,这个是一个交通规范。
你可以在红灯的时候不停,因为此时没有一个障碍物阻碍你。但是如果大家都按照这个约定来执行,那
么不管是交通的顺畅度还是安全性都比较好。
而相对于技术层面来说,约定有很多地方体现,比如一个公司,会有专门的文档格式、代码提交规范、
接口命名规范、数据库规范等等。这些规定的意义都是让整个项目的可读性和可维护性更强。
Spring Boot为什么能够把原本繁琐又麻烦的工作省略掉呢?
实际上这些工作并不是真正意义上省略了,只是Spring Boot帮我们默认实现了。
哪些约定?
Spring Boot的项目结构约定,Spring Boot默认采用Maven的目录结构,其中
src.main.java 存放源代码文件
src.main.resource 存放资源文件
src.test.java 测试代码
src.test.resource 测试资源文件
target 编译后的class文件和jar文件
内置了嵌入式的Web容器,在Spring 2.2.6版本的官方文档中3.9章节中,有说明Spring Boot支持
四种嵌入式的Web容器
Tomcat
Jetty
Undertow
Reactor
Spring Boot默认提供了两种配置文件,一种是application.properties、另一种是
application.yml。Spring Boot默认会从该配置文件中去解析配置进行加载。
Spring Boot通过starter依赖,来减少第三方jar的依赖。
springboot和spring项目的差异
main方法上的@SpringBootApplication()注解
这个注解上比较特殊的包含以下三个
1.@SpringBootConfiguration 包含@Configuration,@Configuration包含@Component
2.@EnableAutoConfiguration
包含
@AutoConfigurationPackage 中有@Import({Registrar.class})
@Import({AutoConfigurationImportSelector.class})
因此关键在于搞明白import注解
3.@ComponentScan 扫描包
import注解
三种使用方法
静态导入
实现importSelector接口,需要重写selectImports方法。@Import({AutoConfigurationImportSelector.class})就是这种,因此springboot最关键的地方在于这个方法
实现ImportBeanDefinitionRegistrar接口
EnableAutoConfiguration
主要作用其实就是帮助springboot应用把所有符合条件的@Configuration配置都加载到当前SpringBoot创建并使用的IoC容器中。
源码-自动加载全流程
Spring Boot配置文件加载全流程
又名:自动装配流程,公共Starter的实现方式,第三方jar引入容器原理
main函数中
ConfigurableApplicationContext app=SpringApplication.run(WaterApplication.class, args);
往里进,进几次run方法,最终找到this.refreshContext(context);里面调用spring源码中最核心的refresh方法。
this.prepareContext(context, environment, listeners, applicationArguments, printedBanner);
this.refreshContext(context);//最核心的源码
this.afterRefresh(context, applicationArguments);(延伸)bean生命周期
首先生成BeanDefinition
ConfigurableListableBeanFactory beanFactory = this.obtainFreshBeanFactory();
跳转
this.refreshBeanFactory();
跳转
this.loadBeanDefinitions(beanFactory);
protected void loadBeanDefinitions(DefaultListableBeanFactory beanFactory) throws BeansException, IOException {
XmlBeanDefinitionReader beanDefinitionReader = new
XmlBeanDefinitionReader(beanFactory);
beanDefinitionReader.setEnvironment(this.getEnvironment());
beanDefinitionReader.setResourceLoader(this);
beanDefinitionReader.setEntityResolver(new ResourceEntityResolver(this));
this.initBeanDefinitionReader(beanDefinitionReader);
}然后生成bean。
this.finishBeanFactoryInitialization(beanFactory);
首先,SpringBoot肯定会执行main方法中的run方法(参数为当前启动类,至于为什么要传这个,下面说),我们的run方法则会执行lOC的初始化操作,这一步和spring项目是一模一样的,最终都会调到refresh方法。
显然,我们的SpringBoot不会走配置文件的初始化,而是根据注解初始化。(重点哦)
我们会将当前的java配置类的类对象传递进去,那么我们会走到Spring BootApplication注解,显然,接下来
我们起作用的就是我们的@EnableAutoConfiguration,引入了AutoConfigurationImportSelector.class重写了selectImports方法,这个方法先去加载我们的spring.factories文件得到候选配置(在2.7的SpringBoot中,加载的是META-INF的spring文件下的imports.文件中的内容)
接下来需要过滤信息的时候,其实就是通过spring-autoconfigure-metadata,propertiesi这个文件中的条件进行筛选,最后这个方法返回要加载的类全限定名,之后便走bean的生命周期,加载到IOC容器中
(延伸,linux shell的配置文件加载顺序)
Spring Boot中的条件过滤
在分析AutoConfigurationImportSelector的源码时,会先扫描spring-autoconfiguration metadata.properties文件,最后再扫描spring.factories对应的类时,会结合前面的元数据进行过滤,
为什么要过滤呢? 原因是很多的@Configuration其实是依托于其他的框架来加载的,如果当前的
classpath环境下没有相关联的依赖,则意味着这些类没必要进行加载,所以,通过这种条件过滤可以有
效的减少@configuration类的数量从而降低SpringBoot的启动时间。
在META-INF/增加配置文件,spring-autoconfigure-metadata.properties。
com.mashibingedu.practice.mashibingConfig.ConditionalOnClass=com.mashibingedu.TestClass格式:自动配置的类全名.条件=值
上面这段代码的意思就是,如果当前的classpath下存在TestClass,则会对mashibingConfig这个
Configuration进行加载
应用-手写Starter
我们通过手写Starter来加深对于自动装配的理解
1.创建一个Maven项目,quick-starter
定义相关的依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
<version>2.1.6.RELEASE</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.56</version>
<!-- 可选 -->
<optional>true</optional>
</dependency> com.mashibingedu.practice.mashibingConfig.ConditionalOnClass=com.mashibingedu.TestClass
public static void main(String[] args) throws IOException {
ConfigurableApplicationContext ac=SpringApplication.run(SpringBootStudyApplication.class, args);
mashibingCore Myc=ac.getBean(mashibingCore.class);
System.out.println(Myc.study());
}2.定义Formate接口
定义的格式转换的接口,并且定义两个实现类
public interface FormatProcessor {
/**
\* 定义一个格式化的方法
\* @param obj
\* @param <T>
\* @return
*/
<T> String formate(T obj);
}
public class JsonFormatProcessor implements FormatProcessor {
@Override
public <T> String formate(T obj) {
return "JsonFormatProcessor:" + JSON.toJSONString(obj);
}
}
public class StringFormatProcessor implements FormatProcessor {
@Override
public <T> String formate(T obj) {
return "StringFormatProcessor:" + obj.toString();
}
}
3.定义相关的配置类
首先定义格式化加载的Java配置类
@Configuration
public class FormatAutoConfiguration {
@ConditionalOnMissingClass("com.alibaba.fastjson.JSON")
@Bean
@Primary // 优先加载
public FormatProcessor stringFormatProcessor(){
return new StringFormatProcessor();
}
@ConditionalOnClass(name="com.alibaba.fastjson.JSON")
@Bean
public FormatProcessor jsonFormatProcessor(){
return new JsonFormatProcessor();
}
}定义一个模板工具类
public class HelloFormatTemplate {
private FormatProcessor formatProcessor;
public HelloFormatTemplate(FormatProcessor processor){
this.formatProcessor = processor;
}
public <T> String doFormat(T obj){
StringBuilder builder = new StringBuilder();
builder.append("Execute format : ").append("<br>");
builder.append("Object format result:"
).append(formatProcessor.formate(obj));
return builder.toString();
}
}再就是整合到SpringBoot中去的Java配置类
@Configuration
@Import(FormatAutoConfiguration.class)
public class HelloAutoConfiguration {
@Bean
public HelloFormatTemplate helloFormatTemplate(FormatProcessor formatProcessor){
return new HelloFormatTemplate(formatProcessor);
}
}4.创建spring.factories文件
在resources下创建META-INF目录,再在其下创建spring.factories文件
install 打包,然后就可以在SpringBoot项目中依赖改项目来操作了。
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\ org.mashibingedu.autoconfiguration.HelloAutoConfiguration5.测试-使用
在SpringBoot中引入依赖
<dependency>
<groupId>org.example</groupId>
<artifactId>format-spring-boot-starter</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency> 在controller中使用
@RestController
public class UserController {
@Autowired
private HelloFormatTemplate helloFormatTemplate;
@GetMapping("/format")
public String format(){
User user = new User();
user.setName("BoBo");
user.setAge(18);
return helloFormatTemplate.doFormat(user);
}
}应用-如何向容器中加入一个bean?
xml文件
注解
springboot主要使用注解,因此侧重介绍注解
本包及子包
使用@Component等派生注解
只要在类上加类上加 @Component 注解即可,该注解只要被扫描到就会注入到spring的bean容器中。
@Component
public class AnoDemoBean {
}当然不只是@Component注解可以声明Bean,还有如:@Repository、@Service、@Controller 等常用注解同样可以。
如果去看这些注解,就发现这些注解上本身就有加 @Component 注解
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Component //可以看到@Service注解上有添加@Component, @Repository和@Controller也一样。
public @interface Service {
@AliasFor(
annotation = Component.class
)
String value() default "";
}这系列注解的出现,给我们带来了极大的便利。我们不需要像以前那样在bean.xml文件中配置bean了,现在只用在类上加上相关注解,就能轻松完成bean的定义。
这四种注解在功能上其实没有特别的区别,不过在业界有个不成文的约定:
- Controller 一般用在控制层
- Service 一般用在业务层
- Repository 一般用在数据层
- Component 一般用在公共组件上
@Bean定义方式
这种方式,主要是结合Configuration来定义bean,首先是声明一个配置类,而后再配置类中,经过返回bean对象的方法形式来声明bean,通常使用姿式以下
@Data
public class ConfigDemoBean {
}
@Configuration
public class BeanLoadConfig {
@Bean
public ConfigDemoBean configDemoBean() {
return new ConfigDemoBean();
}
}注意!配置类自己也被Spring容器看为一个Bean。
(拓展)@Component 与@Bean区别
1)作用对象不同:@Component 注解作用于类,而 @Bean 注解作用于方法。
这样的特点会让 @Bean 方式更加灵活。比如当我们引用第三方库中的类需要装配到 Spring 容器时,只能通过 @Bean 来实现。
比如
@Configuration
public class WireThirdLibClass {
@Bean
public ThirdLibClass getThirdLibClass() {
//第三方的ThirdLibClass类
return new ThirdLibClass();
}
}再比如
@Bean
public OneService getService(status) {
case (status) {
when 1:
return new serviceImpl1();
when 2:
return new serviceImpl2();
when 3:
return new serviceImpl3();
}
}这两点都是@Component无法做到,只能@Bean实现,所以说@Bean更加灵活。
2)@Component通常是通过类路径扫描来自动装配到Spring容器中。而@Bean通常我们会在该注解的方法中定义产生这个bean的逻辑。
我们可以加一些@Conditional,@ConditionalOnBean等等一些注解来控制是否声明该Bean,不会一开始就自动装配到Spring容器中。
比如
public class MacCondition implements Condition {
@Override
public boolean matches(ConditionContext conditionContext, AnnotatedTypeMetadata annotatedTypeMetadata) {
Environment environment = conditionContext.getEnvironment();
String property = environment.getProperty("os.name");
if (property.contains("Mac")) {
log.info("当前操作系统是:Mac OS X");
return true;
}
return false;
}
}
@Configuration
public class ConditionalConfig {
/**
* 如果MacCondition的实现方法返回true,则注入这个bean
*/
@Bean("mac")
@Conditional({MacCondition.class})
public SystemBean systemMac() {
log.info("ConditionalConfig方法注入 mac实体");
return new SystemBean("Mac ios系统","001");
}
}上面的例子表示,如果当前操作系统是Mac,才会注入当前Bean。这个也只能 @Bean 注解才能实现。
总结:@Component和@Bean都是用来注册Bean并装配到Spring容器中,但是Bean比Component的自定义性更强。可以实现一些Component实现不了的自定义加载类。
第三方包
如果上面的注解加在当前项目中,那么当SpingBoot主类启动的时候,@SpringBootApplication注解会默认去扫描的本包和它的子包的所有需要装配的类,自动装配到spring的bean容器中。
但是如果你提供了一个Jar包供第三方用户使用,那么你这个jar包中的Bean,能被第三方加载么?
这就要看你当前项目的包名和你你引用的第三方Jar包的包名了。如果是它的子包,则可以,否则不行。
如果你当前项目本包的地址是com.jincou 而你引用的第三方Jar的本包是 com.third,那么也就是第三方Jar的Bean无法被扫描到,所以也就无法注入到Spring容器中。
比如这里有个第三方的Bean。要如何做才能被扫描注入到Spring容器中呢。
package com.third.bean;
import org.springframework.stereotype.Component;
/**
* @Description: 这个bean作为第三方bean 给依赖该jar包的项目使用
*/
@Component
public class ThirdComponentBean {
private String type = "第三方ThirdComponent注解生成bean实体";
}@ComponentScan
很简单,既然@SpringBootApplication注解默认扫描只是当前项目的本包和它的子包,那就想办法让它扫描第三方jar的包就好了。
/**
* @Description: Springboot 启动类
*/
@ComponentScan(basePackages ={"com.third.bean"})
@SpringBootApplication()
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class);
}
}@ComponentScan主要就是定义扫描的路径从中找出标识了需要装配的类自动装配到spring的bean容器中。
需要装配的类也就是上面加了@Controller,@Service,@Repository,@Component,@Configuration等等的注解的Bean到IOC容器中。
这里不一定要加在启动类上,你可以加在加在装配的类上,但建议加在启动类上,比较直观,后期如果要改动或者去除也比较好找。
@Import注解
@ComponentScan是扫描整个包,但其实你可能只需注入一个或者几个指定的Bean,那我们可以考虑用 @Import 注解
@Import(value= com.third.bean.ThirdComponentBean.class)
@SpringBootApplication()
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class);
}
}这样做同样也会成功的将ThirdComponentBean对象注入到Spring的bean容器中。
spring.factories
上面两种注入方式都有个很明显缺点,就是如果我需要引用外部jar包的Bean的时候,都需要在当前项目配置 @ComponentScan 或者 @Import 去扫描才能注入当前Bean,这样显然不够友好。
可不可以当前项目什么都不做就可以直接引用第三方jar的Bean呢?
当然可以。
我们只需要在将配置放在第三方jar指定的文件中即可,使用者会自动加载,从而避免的代码的侵入
- 在资源目录下新建目录 META-INF
- 在 META-INF 目录下新建文件 spring.factories
- 在文件中添加下面配置
org.springframework.boot.autoconfigure.EnableAutoConfiguration=com.third.bean.ConfigurationBean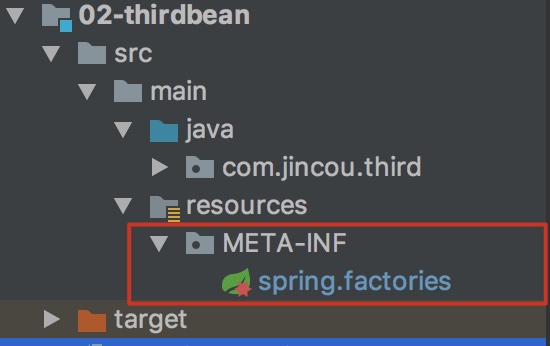
最后,注意。当然啦,第三方包需要先在pom文件中dependencies中加入,或者添加jar包
还需注意,第三方的代码里面同样需要是spring项目,带有@Component等注解,否则只能自己在@Bean注解的方法中new对象。
controller不是线程安全的
注解 @Scope(“prototype”) ,将Controller设置为多例模式。
Controller 中使用 ThreadLocal 变量。
spring事务
原理
Spring事务的本质其实就是数据库对事务的支持,没有数据库的事务支持,spring是无法提供事务功能的。对于纯JDBC操作数据库,想要用到事务,可以按照以下步骤进行:
- 获取连接 Connection con = DriverManager.getConnection()
- 开启事务con.setAutoCommit(true/false);
- 执行CRUD
- 提交事务/回滚事务 con.commit() / con.rollback();
- 关闭连接 conn.close();
使用Spring的事务管理功能后,我们可以不再写步骤 2 和 4 的代码,而是由Spirng 自动完成。
1、@Transactional 声明目标方法后,Spring Framework 默认使用 AOP 代理,代码运行时生成一个代理对象,根据 @Transactional 的属性配置,代理对象决定该声明 @Transactional 的目标方法是否由拦截器 TransactionInterceptor 来使用拦截。
2、在 TransactionInterceptor 拦截时,会在目标方法开始执行之前创建并加入事务,并执行目标方法的逻辑, 最后根据执行情况是否出现异常,利用抽象事务管理器 AbstractPlatformTransactionManager 操作数据源 DataSource 提交或回滚事务。
3、Spring AOP 代理有 CglibAopProxy 和 JdkDynamicAopProxy 两种,以 CglibAopProxy 为例,对于 CglibAopProxy,需要调用其内部类的 DynamicAdvisedInterceptor 的 intercept 方法。对于 JdkDynamicAopProxy,需要调用其 invoke 方法。
4、默认的代理模式下,只有目标方法由外部调用,才能被 Spring 事务拦截器拦截。在同一个类中的两个方法直接调用,是不会被 Spring 的事务拦截器拦截。
使用
@Transactional
| 属性 | 类型 | 描述 |
|---|---|---|
| value | String | 可选。限定描述符,指定使用的事务管理器 |
| propagation | enum: Propagation | 可选。事务传播行为设置。 |
| isolation | enum: Isolation | 可选。事务隔离级别设置。默认服从数据源的配置。 |
| readOnly | boolean | 读写或只读事务,默认读写 |
| timeout | int (in seconds granularity) | 事务超时时间设置 |
| rollbackFor | Class对象数组,必须继承自Throwable | 导致事务回滚的异常类数组 |
| rollbackForClassName | 类名数组,必须继承自Throwable | 导致事务回滚的异常类名字数组 |
| noRollbackFor | Class对象数组,必须继承自Throwable | 不会导致事务回滚的异常类数组 |
| noRollbackForClassName | 类名数组,必须继承自Throwable | 不会导致事务回滚的异常类名字数组 |
事务传播机制
| 常量名称 | 常量解释 |
|---|---|
| PROPAGATION_REQUIRED | 支持当前事务,如果当前没有事务,就新建一个事务。这是最常见的选择,也是 Spring 默认的事务的传播。 |
| PROPAGATION_REQUIRES_NEW | 新建事务,如果当前存在事务,把当前事务挂起。新建的事务将和被挂起的事务没有任何关系,是两个独立的事务,外层事务失败回滚之后,不能回滚内层事务执行的结果,内层事务失败抛出异常,外层事务捕获,也可以不处理回滚操作 |
| PROPAGATION_SUPPORTS | 支持当前事务,如果当前没有事务,就以非事务方式执行。 |
| PROPAGATION_MANDATORY | 支持当前事务,如果当前没有事务,就抛出异常。 |
| PROPAGATION_NOT_SUPPORTED | 以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。 |
| PROPAGATION_NEVER | 以非事务方式执行,如果当前存在事务,则抛出异常。 |
| PROPAGATION_NESTED | 如果一个活动的事务存在,则运行在一个嵌套的事务中。如果没有活动事务,则按REQUIRED属性执行。它使用了一个单独的事务,这个事务拥有多个可以回滚的保存点。内部事务的回滚不会对外部事务造成影响。它只对DataSourceTransactionManager事务管理器起效。 |
常见误区-同类中调用
需要调用者方法上也加@Transactionl ,否则无论 被调用方法上面加不加 @Transaction 此时事务不会开启。
就算加了,也要注意,默认代理模式下,如果调用者自己已经有事务,则被调用的永远和它处于同一事务。被调用者的设置的 REQUIRES_NEW、NOT_SUPPORTED、NEVER 等等都不会有效。
这个时候可以通过维护一个自身实例的代理来解决。
其他误区
| 失效场景 | 描述 |
|---|---|
| @Transactional 应用在非 public 修饰的方法上 | 只能标记在 public 修饰的方法上。 jdk是代理接口,私有方法必然不会存在在接口里,所以就不会被拦截到; cglib是子类,private的方法照样不会出现在子类里,也不能被拦截。 |
| @Transactional 注解传播属性 propagation 设置错误 | 类与类相互调用时,被调用者可以新开事务,不加入调用者事务 |
| @Transactional 注解回滚异常属性 rollbackFor 设置错误 | 默认配置下 Spring 只会回滚运行时异常(非受检查异常),即继承自 RuntimeException 的异常或者 Error。 |
| 异常被 catch 捕获,没有继续往外抛,导致 @Transactional 失效 | 使用 try{}catch{}捕获处理了异常,则事务不再回滚,如果想让事务回滚,则必须继续往外抛。 |
| 数据库存储引擎不支持事务导致失效 | Spring Data JPA 默认使用 MyISAM 作为 Mysql 的存储引擎,此引擎不支持事务、不支持外键。InnoDB 存储引擎支持事务,可以在配置文件中进行指定。 |
spring aop和aspectj的区别
spring aop
1、基于动态代理来实现,默认如果使用接口的,用JDK提供的动态代理实现,如果是方法则使用CGLIB实现
2、Spring AOP需要依赖IOC容器来管理,并且只能作用于Spring容器,使用纯Java代码实现
3、在性能上,由于Spring AOP是基于动态代理来实现的,在容器启动时需要生成代理实例,在方法调用上也会增加栈的深度,使得Spring AOP的性能不如AspectJ的那么好
aspectj
AspectJ属于静态织入,通过修改代码来实现,有如下几个织入的时机:
1、编译期织入(Compile-time weaving): 如类 A 使用 AspectJ 添加了一个属性,类 B 引用了它,这个场景就需要编译期的时候就进行织入,否则没法编译类 B。
2、编译后织入(Post-compile weaving): 也就是已经生成了 .class 文件,或已经打成 jar 包了,这种情况我们需要增强处理的话,就要用到编译后织入。
3、类加载后织入(Load-time weaving): 指的是在加载类的时候进行织入,要实现这个时期的织入,有几种常见的方法。1、自定义类加载器来干这个,这个应该是最容易想到的办法,在被织入类加载到 JVM 前去对它进行加载,这样就可以在加载的时候定义行为了。2、在 JVM 启动的时候指定 AspectJ 提供的 agent:-javaagent:xxx/xxx/aspectjweaver.jar。
- AspectJ可以做Spring AOP干不了的事情,它是AOP编程的完全解决方案,Spring AOP则致力于解决企业级开发中最普遍的AOP(方法织入)。而不是成为像AspectJ一样的AOP方案
- 因为AspectJ在实际运行之前就完成了织入,所以说它生成的类是没有额外运行时开销的
| Spring AOP | AspectJ |
|---|---|
| 在纯 Java 中实现 | 使用 Java 编程语言的扩展实现 |
| 不需要单独的编译过程 | 除非设置 LTW,否则需要 AspectJ 编译器 (ajc) |
| 只能使用运行时织入 | 运行时织入不可用。支持编译时、编译后和加载时织入 |
| 功能不强-仅支持方法级编织 | 更强大 – 可以编织字段、方法、构造函数、静态初始值设定项、最终类/方法等……。 |
| 只能在由 Spring 容器管理的 bean 上实现 | 可以在所有域对象上实现 |
| 仅支持方法执行切入点 | 支持所有切入点 |
| 代理是由目标对象创建的, 并且切面应用在这些代理上 | 在执行应用程序之前 (在运行时) 前, 各方面直接在代码中进行织入 |
| 比 AspectJ 慢多了 | 更好的性能 |
| 易于学习和应用 | 相对于 Spring AOP 来说更复杂 |
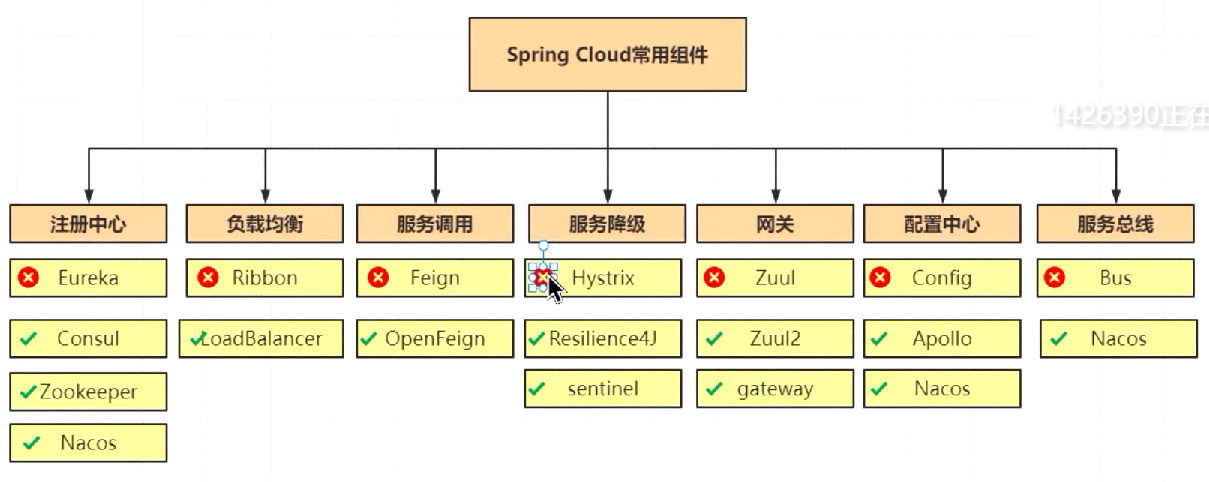
SpringCloud

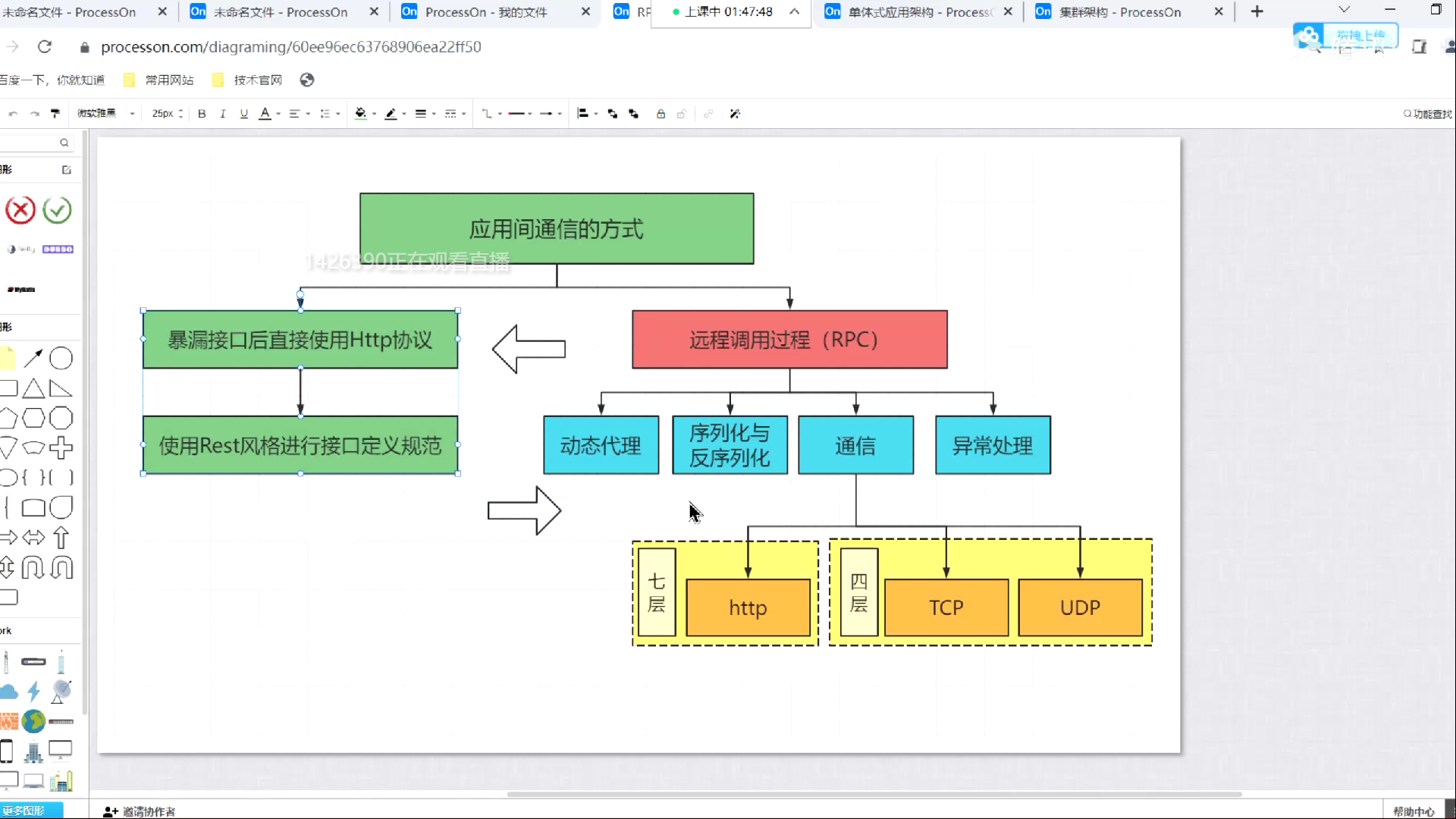
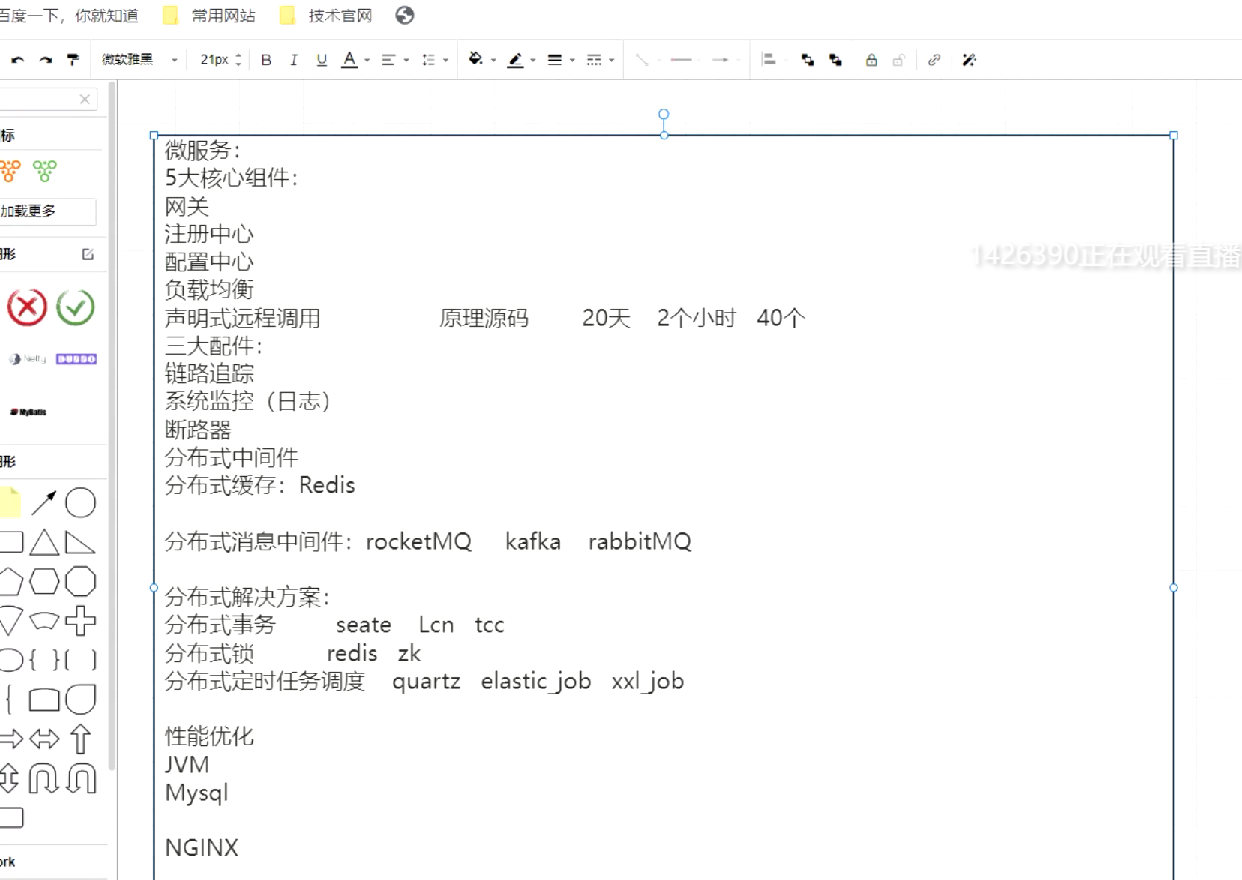
quartz
Quartz是Java领域最著名的开源任务调度工具。Quartz提供了极为广泛的特性如持久化任务,集群和分布式任务
Quartz的集群部署方案在架构上是分布式的,没有负责集中管理的节点,而是利用数据库锁的方式来实现集群环境下进行并发控制。
为什么选择Quartz,优点
Quartz是Java领域最著名的开源任务调度工具。Quartz提供了极为广泛的特性如持久化任务,集群和分布式任务等,其特点如下:
-
完全由Java写成,方便集成(Spring),配置较为简单
-
伸缩性
-
负载均衡
-
高可用性,当集群中其中的一个节点出问题时,另外的节点接手任务,继续工作。确保所有的job的到执行。
quartz缺点?
单点故障。Quartz可以在同一台机器上运行所有节点,也可以在不同的机器上运行。如果所有节点是跑在同一台机器的时候,我们称之为垂直集群。对于垂直集群,存在着单点故障的问题,挂一台全部挂。
为了解决单点故障,就要搭建水平集群,放置在不同的机器上时。但是也会有新的缺点,时间,我们的时钟时间必须要同步,以免出现离奇且不可预知的行为。
线程模型
在Quartz中有两类线程:Scheduler调度线程和任务执行线程。
任务执行线程:Quartz不会在主线程(QuartzSchedulerThread)中处理用户的Job。Quartz把线程管理的职责委托给ThreadPool,一般的设置使用SimpleThreadPool。SimpleThreadPool创建了一定数量的WorkerThread实例来使得Job能够在线程中进行处理。WorkerThread是定义在SimpleThreadPool类中的内部类,它实质上就是一个线程。
Quartz集群同步机制
同步就要使用锁来进行,本质上是悲观锁。
锁在哪存着呢?一张叫Quartz_locks的表,里面有五把锁,分别代表不同业务。
CALENDAR_ACCESS。日历访问
JOB_ACCES。任务访问
MISFIRE_ACCESS。失败访问
STATE_ACCESS。状态访问
TRIGGER_ACCESS。触发器访问。触发器cron表达式。
每当要进行与某种业务相关的数据库操作时,先去QRTZ_LOCKS表中查询操作相关的业务对象所需要的锁,在select语句之后加for update来实现。例如,TRIGGER_ACCESS表示对任务触发器相关的信息进行修改、删除操作时所需要获得的锁。这时,执行查询这个表数据的SQL形如:
select * from QRTZ_LOCKS t where t.lock_name='TRIGGER_ACCESS' for update当一个线程使用上述的SQL对表中的数据执行查询操作时,若查询结果中包含相关的行,数据库就对该行进行ROW LOCK;若此时,另外一个线程使用相同的SQL对表的数据进行查询,由于查询出的数据行已经被数据库锁住了,此时这个线程就只能等待,直到拥有该行锁的线程完成了相关的业务操作,执行了commit动作后,数据库才会释放了相关行的锁,这个线程才能继续执行。
通过这样的机制,在集群环境下,结合悲观锁的机制就可以防止一个线程对数据库数据的操作的结果被另外一个线程所覆盖,从而可以避免一些难以觉察的错误发生。当然,达到这种效果的前提是需要把Connection设置为手动提交,即autoCommit为false。
https://tech.meituan.com/2014/08/31/mt-crm-quartz.html
设计模式
设计模式是什么?即Design Patterns,是指在软件设计中,被反复使用的一种代码设计经验。
谁提出的?设计模式这个术语是上个世纪90年代由Erich Gamma、Richard Helm、Raplh Johnson和Jonhn Vlissides四个人总结提炼出来的,并且写了一本Design Patterns的书。这四人也被称为四人帮(GoF)。
为什么要使用设计模式?根本原因还是软件开发要实现可维护、可扩展。
怎么做?就必须尽量复用代码,并且降低代码的耦合度。
设计模式主要是基于OOP编程提炼的,它基于以下7个原则:
开闭原则
由Bertrand Meyer提出的开闭原则(Open Closed Principle)是指,软件应该对扩展开放,而对修改关闭。这里的意思是在增加新功能的时候,能不改代码就尽量不要改,如果只增加代码就完成了新功能,那是最好的。
具体实现:面向抽象编程。用抽象构建框架,用实现扩展细节。
举例:商品类。如果要增加打折活动,重新实现一个类,继承自原有的类。
里氏替换原则
定义:对开闭原则的补充,继承必须确保超类所拥有的性质在子类中仍然成立。即如果我们调用一个父类的方法可以成功,那么替换成子类调用也应该完全可以运行。子类可以扩展父类的功能,但不能改变父类原有的功能,尽量不要重写父类的方法。
如果要重写:则入参应更宽松,返回值应更严格。
违反后修正:取消原来的继承关系,重新设计它们之间的关系。
举例:企鹅、鸵鸟和几维鸟从生物学的角度来划分,它们属于鸟类;但从类的继承关系来看,由于它们不能继承“鸟”会飞的功能,所以它们不能定义成“鸟”的子类。
依赖倒置原则
定义:高层模块不应该依赖低层模块,二者都应该依赖其抽象。即高层模块应通过底层模块的接口去调用。
◆抽象不应该依赖细节;细节应该依赖抽象
◆针对接口编程,不要针对实现编程
优点:可以减少类间的耦合性
实现:A如果要使用B,B又是一类需要拓展,则A使用B的接口,不使用具体实现。这样后续拓展B,不需要更改A
举例:学生学习课程。每种课程有不同的学习方法。则课程抽象出一个学习的接口,学生调用课程的接口方法。这样如果有新课程,则不需要修改学生。
单一职责原则
定义:不要存在多余一个导致类变更的原因。
一般 接口,方法使用单一职责。类的单一职责用的少一些。
优点:减少耦合,提高可维护性,降低变更的风险。
实现:把类拆分,接口拆分,方法中如果有ifelse,也可拆分。
接口隔离原则
定义:用多个专门的接口,而不是单一的总接口。(接口,可以从抽象的角度理解如后端提供的接口,也可以具体的java接口)
原则:适度。
实现:拆
迪米特法则,最少知道原则
定义:一个对象应该对其他对象保持最少的了解。
实现:强调只跟朋友交流。朋友指的是,出现在成员变量,方法的入参和出参中的类。方法内部的类不是朋友类。
合成/复用原则(组合/复用原则)
定义:尽量使用对象组合,而不是继承来达到复用的目的。
举例:大部分实体是属于组合实现的。比如汽车飞机,继承相对于更加抽象比如规则与概念。
设计模式把一些常用的设计思想提炼出一个个模式,然后给每个模式命名,这样在使用的时候更方便交流。GoF把23个常用模式分为创建型模式、结构型模式和行为型模式三类,我们后续会一一讲解。
学习设计模式,关键是学习设计思想,不能简单地生搬硬套,也不能为了使用设计模式而过度设计,要合理平衡设计的复杂度和灵活性,并意识到设计模式也并不是万能的。
创造型模式
创建型模式关注点是如何创建对象,其核心思想是要把对象的创建和使用相分离,这样使得两者能相对独立地变换。
创建型模式包括:
- 工厂方法:Factory Method
- 抽象工厂:Abstract Factory
- 建造者:Builder
- 原型:Prototype
- 单例:Singleton
工厂方法
定义:定义一个创建对象的接口,让实现这个接口的类来决定如何实例化。
适用场景:应用层不依赖于产品类的实例如何被创建,只管用就行。创建对象需要大量代码。
符合开闭原则。
在源码中的体现,collection接口的iterator方法,arraylist实现类中也有iterator方面,创建了自己的iterator并返回。
spring中的 BeanDefinitionReader接口,有XmlBeanDefinitionReader,PropertiesBeanDefinitionReader,groovyBeanDefinitionReader。门面模式
urlstramhandlerfactory有各种协议的handler
logback中iloggerfactory中有getlogger方法,根据名字返回需要的实现。
抽象工厂
定义:无需指定具体的类。
产品族,产品级。多了一个维度。本来是一个工厂一次生产一个产品。现在一个工厂可以生产多个产品,变成了产品族。
不同课程是同一产品级。课程+笔记是一个产品族。
源码举例:java.sql.connection接口
有一堆返回值为statement,preparestatement的方法。
mysql的jdbc中有接口的实现。
mybatis有sqlsessionfactory接口。具体实现为了创建一个sqlsession对象,先获取环境变量,再创建事务,并用这个事务创建出执行器。最终才根据配置,执行器创建出一个defaultSqlSession对象。
单例模式
单例模式,通常用在重量级的对象,一个类只有一个实例,构造器私有化,通过唯一一个公有静态getInstance方法获取实例,实例在哪?在一个static变量里new后存着。 那么会有一个问题,两个东西,有四种状态,全static,不全,全不为static。
方法不为static,则需要先实例化类,就违反了需求,存储实例的变量不为static,同样需要先实例化,且静态方法无法调用非静态成员。都不为static,则会出现栈溢出,无限循环创建对象。因此即使通过排除法,也只能全为static才能达到我们的需求。
饿汉式与懒汉式区别,饿汉式在类加载时(如使用他的某一个静态变量就可以触发类加载)即被创建。
懒汉式不用getInstance方法时,不被创建,反复调用时返回上次创建的对象。存在线程不安全,判断==null时后,没new前,第二个线程来了,也判断==null,则两个线程都会new。饿汉式不会线程不安全吗?对的,因为JVM在类加载的过程,保证了不会初始化多个static对象。
java.lang.runtime就是单例模式,饿汉式
spring bean默认为单例,但他既不是饿汉式,也不是懒汉式。而是有一套自己的机制,生命周期,在applicationcontext初始化的时候,创建的。
如果从框架的使用角度看,则算是饿汉式,不是getbean的时候才创建。
从框架内部实现来看,则是懒汉式。
建造者模式
当创造一个对象需要很多步骤时。
与工厂模式相比,更关注过程,产品不是一样的。
stringbuilder append方法,返回自身。
stringbuffer 加了同步方法
BeanDefinitionBuilder。
mybatis的sqlsession类,除了刚才说的抽象工厂构造,还提供了Builder。里面还嵌套了一个xmlconfigbuilder。
演进版本:内部静态构造类,链式调用,返回自己,最后build。
原型
通过拷贝创建新的对象。实现cloneable接口。
注意浅拷贝和深拷贝。当克隆的对象中有引用对象,拷贝会导致共用同一对象。需要在clone方法中单独调用克隆,变为深拷贝。
适用场景:对象创建复杂。如循环中需要大量创建对象。
防止克隆破坏单例,实现clonable接口,返回当前实例。或者不要实现clonable接口。
源码:arraylist hashmap都有实现clonable接口
(延伸)hashcode不一定是地址。要看具体实现。如果想要获取地址,需要native方法,可通过unsafe中的方法调用。也可自行使用c++编写动态链接库,用jni调用。因为c++中可以直接获取到地址。
https://www.iteye.com/blog/bijian1013-2300961
结构型模式
门面模式
符合迪米特法则,不符合开闭原则(新增子模块,需要修改门面)
是指提供一个统一的接口去访问多个子系统的多个不同的接口。
只需调用门面,门面会去和各个子系统打交道。
代理模式(也比较重要,主要知道他的应用)
适用场景:保护,增强。
分类:静态代理(在代码中显式定义了一个实现类的代理,对同名的方法进行包装),动态代理(动态生成),CGLIB代理(通过继承实现,重写方法,注意final)
java提供了动态代理。
动态代理只能代理接口,不能代理类,动态创建了class文件
应用:spring aop
(延伸)
Spring代理选择-扩展
当Bean有实现接口时,Spring就会用JDK的动态代理
当Bean没有实现接口时,Spring使用CGlib
可以强制使用Cgib
在springi配置中加入
参考资料:https://docs..spring..io/spring/docs/,current//spring–framework-reference/core.html
适配器模式
定义:将一个类的接口转换成客户期望的另一个接口,使原本接口不兼容的类可以一起工作
适配器-适用场景
◆已经存在的类,它的方法和需求不匹配时(方法结果相同或相似)
◆不是软件设计阶段考虑的设计模式,是随着软件维护,由于不同产品、不同厂家造成功能类似而接口不相同情况下的解决方案
符合开闭原则
类适配器,通过继承。
对象适配器,
桥接模式
定义:将抽象部分与它的实现部分分离,使它们都可以独立地变化。
思想:即不要过度使用继承,而是优先拆分某些部件,使用组合的方式来扩展功能。
使用桥接模式的好处在于,如果要增加一种引擎,只需要针对Engine派生一个新的子类,如果要增加一个品牌,只需要针对RefinedCar派生一个子类,任何RefinedCar的子类都可以和任何一种Engine自由组合,即一辆汽车的两个维度:品牌和引擎都可以独立地变化。
实现类的数量从n*m变为n+m
┌───────┐
│ Car │
└───────┘
▲
┌──────────────────┼───────────────────┐
│ │ │
┌───────┐ ┌───────┐ ┌───────┐
│BigCar │ │TinyCar│ │BossCar│
└───────┘ └───────┘ └───────┘
▲ ▲ ▲
│ │ │
│ ┌───────────────┐│ ┌───────────────┐│ ┌───────────────┐
├─│ BigFuelCar │├─│ TinyFuelCar │├─│ BossFuelCar │
│ └───────────────┘│ └───────────────┘│ └───────────────┘
│ ┌───────────────┐│ ┌───────────────┐│ ┌───────────────┐
├─│BigElectricCar │├─│TinyElectricCar│├─│BossElectricCar│
│ └───────────────┘│ └───────────────┘│ └───────────────┘
│ ┌───────────────┐│ ┌───────────────┐│ ┌───────────────┐
└─│ BigHybridCar │└─│ TinyHybridCar │└─│ BossHybridCar │
└───────────────┘ └───────────────┘ └───────────────┘ ┌───────────┐
│ Car │
└───────────┘
▲
│
┌───────────┐ ┌─────────┐
│RefinedCar │ ─ ─ ─>│ Engine │
└───────────┘ └─────────┘
▲ ▲
┌────────┼────────┐ │ ┌──────────────┐
│ │ │ ├─│ FuelEngine │
┌───────┐┌───────┐┌───────┐ │ └──────────────┘
│BigCar ││TinyCar││BossCar│ │ ┌──────────────┐
└───────┘└───────┘└───────┘ ├─│ElectricEngine│
│ └──────────────┘
│ ┌──────────────┐
└─│ HybridEngine │
└──────────────┘虚线表示使用。
public abstract class RefinedCar extends Car {
public RefinedCar(Engine engine) {
super(engine);
}
public void drive() {
this.engine.start();//在这里使用引擎
System.out.println("Drive " + getBrand() + " car...");
}
public abstract String getBrand();
}
RefinedCar car = new BossCar(new HybridEngine());
car.drive();避免直接继承带来的子类爆炸。
行为型模式
观察者模式(知道下应用和大致原理就行)
模版方法模式
责任链模式
nginx
一些设计良好的高性能进程,比如nginx,都是实际上有几颗CPU,就配几个工作进程,道理就在这。比如你的服务器有8颗CPU,那么nginx worker应当只有8个,当你多于8个时,内核可能会放超过多个nginx worker进程到1个runqueue里,会发生什么呢?就是在这颗CPU上,会比较均匀的把时间分配给这几个nginx worker,每个worker进程运行完一个时间片后,内核需要做进程切换,把正在运行的进程上下文保存下来。假设内核分配的时间片是100ms,做进程切换的时间是5ms,那么进程性能下降还是很明显的,跟你配置的worker有关,越多下降得越厉害。
当然,这是跟nginx的设计有关的。nginx是事件驱动的全异步进程,本身设计上就几乎不存在阻塞和中断,nginx的设计者就希望每一个nginx worker可以独占CPU的几乎全部时间片,这点就是nginx worker数量配置的依据所在。
项目
背景
水利部大力推进智慧水利建设。安徽省合肥市已开展浮山路渠小流域水环境综合治理工程,还需要构建一套智慧水务平台,实现信息化。
需求
基本(信息化):采集、存储、分析。实现流域涉水要素全面感知,对全流域截流井-泵站-污水处理设备-除臭设备,管道,河流,气象检测站,监控设备等水利工程设施的实时采集与展示。
进阶(智慧化):模拟、预测。决策辅助支撑和智慧应用系统,实现智能调度。
我的工作
进阶部分需要训练一些调度模型,这部分是团队里的研究生在做。
基本部分全部是我做的。
1.后端项目搭建。
2.数据库选型,采用三种数据库分别存储不同数据
3.鉴权系统,登录,微信登录。
4.实体类定义,建表,并用定时任务采集数据入库。
5.提供多种动态数据查询接口。提供统计接口
6.预警信息维护。
7.大华监控抓图对接,云台控制。
8.字段映射功能
9.备份脚本
10.服务器环境配置与部署
设计选型
防火墙
负载均衡nginx
安全鉴权框架
数据库mysql,redis,elasticsearch
为什么用es不用时序性数据库
- 数据量:是否海量数据,单表数据量太大会考验数据库的性能
- 数据结构:结构化 (每条记录的结构都一样) 还是非结构化的 (不同记录的结构可以不一样)
- 是否宽表:一条记录是 10 个域,还是成百上千个域
- 数据属性:是基本数据 (比如用户信息)、业务数据 (比如用户行为)、辅助数据 (比如日志)、缓存数据
- 是否要求事务性:一个事务由多个操作组成,必须全部成功或全部回滚,不允许部分成功
- 实时性:对写延迟,或读延迟有没有要求,比如有的业务允许写延迟高但要求读延迟低
- 查询量:比如有的业务要求查询大量记录的少数列,有的要求查询少数记录的所有列
- 排序要求:比如有的业务是针对时间序列操作的
- 可靠性要求:对数据丢失的容忍度
- 一致性要求:是否要求读到的一定是最新写入的数据
- 对增删查改的要求:有的业务要能快速的对单条数据做增删查改 (比如用户信息),有的要求批量导入,有的不需要修改删除单条记录 (比如日志、用户行为),有的要求检索少量数据 (比如日志),有的要求快速读取大量数据 (比如展示报表),有的要求大量读取并计算数据 (比如分析用户行为)
- 是否需要支持多表操作
如influxdb集群闭源码后,扩展性不行