数据结构
哈希,散列表
得出对象的key关键码,key可以任意指定
能从key得到存储位置的函数,叫做hash函数,即address=hash(key)
有哪些hash函数呢?
假设hash表大小为m
除留余数法,求余 key%p 除数p为<=m的最接近的质数,且key是几进制的数,p不能是几的幂。
数字分析法,地址有几位,就选key中的几位,具体怎么选呢,选分布均匀的那几位。有个计算均匀度的公式,每一个可能值-期望出现次数的平方和,越小则越均匀。期望出现次数为key的数量除以可能出现的数。要事先知道所有的关键码,每一位的数值分布情况。
平方取中法,关键码的内码(英文为ASCII,中文为GB2312)的平方,然后取中间几位。一般取散列地址总数为8的某次幂。
折叠法,把关键码从左到右,按照散列表的地址位数,分成多个部分,然后叠加起来。移位法按各部分最后一位对齐,分界法不折断来回折叠。位数较多的时候,且数字分布比较均匀时可以这样。
如果算出来的地址范围,比实际表大,则乘以一个比例因子,压缩即可。
解决冲突
闭散列法(开地址法)
线性探测法,每次往后找一个,直到找一圈。
二次探测法,表的大小必须为4k+3的质数,固定最初的位置+-i平方。i<=表的一半。装载因子<=0.5
双散列法,类似线性探测法,但是每次位移量为另一个hash的值(也叫伪随机数),要求位移量小于表的长度m,且与m互质。最多m-1次
开散列法
用链表,每个节点是一个桶,重复了就往桶的链表结尾加一个。
MYSQL数据库部分
使用方面
查询操作
基本查询 SELECT * FROM <表名>
条件查询 SELECT * FROM <表名> WHERE <条件表达式> 多个条件用AND连接
投影查询 SELECT 列1 别名1, 列2 别名2, 列3 别名3 FROM ...
排序 SELECT 列1, 列2, 列3 FROM students ORDER BY 列1 DESC, 列2
分页查询 LIMIT <M> OFFSET <N> # 每页最多M条记录,OFFSET是0索引,返回[N,N+M)的数据
聚合查询 SELECT COUNT(*) num FROM <表名> ; # 结果仍是二维表,有列名
多表查询又叫笛卡尔查询,先两两相连,列数为积。然后根据where条件筛除。
连接查询,连接查询是另一种类型的多表查询。连接查询对多个表进行JOIN运算,简单地说,就是先确定一个主表作为结果集,然后,把其他表的行有选择性地“连接”在主表结果集上。JOIN查询需要先确定主表,然后把另一个表的数据“附加”到结果集上
INNER JOIN, LEFT OUTER,RIGHT JOIN, OUTER JOIN, FULL OUTER JOIN 指的是 on 条件
SELECT ... FROM <表1> INNER JOIN <表2> ON <条件...>;对象关系映射,字段不同的三种处理方法,查询的时候用别名,注解,mapper文件
(延伸,分页查询确定总数)
确定总数 select count(id) from students; 注意:count 函数计算的一定是主键字段
确定总页数 SELECT CEILING(COUNT(*) / 3) FROM students;
CEILING 向上取整
(延伸,随着N的增大,查询速度越来越慢?)
放弃总页数的精确计算,即不使用count。根据业务选择一个带索引的列来分页,比如id
假设每页查询100条:
第一页查询:select * from xxx where id>=0 limit 101
如果返回101条记录,说明有下一页,继续查第二页:
select * from xxx where id>=? limit 101 其中参数是上一次查询的最后一条记录的id
查到某一页返回结果数量<101,即为最后一页
即:
def getNextPage(int offsetId=0, int limit=101):
results = execute("select * from xxx where id >= ? limit ?", offsetId, limit)
if len(results)==limit:
return results[:-1], results[limit-1].id # 返回100条记录+最后一条记录的id
else:
return results, None # 最后一页(延伸,聚合)
不止COUNT,SUM AVG MAX MIN,其中SUM和AVG要求数值类型,MAX和MIN不要求
如果是字符类型,MAX()和MIN()会返回排序最后和排序最前的字符。对字符型数据的最大值,是按照首字母由A~Z的顺序排列,越往后,其值越大。当然,对于汉字则是按照其全拼拼音排列的,若首字符相同,则比较下一个字符,以此类推。当然,对与日期时间类型的数据也可以求其最大/最小值,其大小排列就是日期时间的早晚,越早认为其值越小
SELECT COUNT(*) boys FROM students WHERE gender = ‘M’;
SELECT AVG(score) average FROM students WHERE gender = ‘M’;
要特别注意:如果聚合查询的WHERE条件没有匹配到任何行,COUNT()会返回0,而SUM()、AVG()、MAX()和MIN()会返回NULL:
(延伸,聚合分组)
SELECT class_id, COUNT(*) num FROM students GROUP BY class_id;
也可以多个组
SELECT class_id, gender, COUNT(*) num FROM students GROUP BY class_id, gender;
(延伸,java分组)
//采用反射,实现匹配任意给定属性的值
List<Object> resultList = new ArrayList<>();
Field f1 = Type.getDeclaredField(groupParm.getAttribute());
f1.setAccessible(true);
for (Object o : detailList) {
String value = String.valueOf(f1.get(o));
if (value.equals(groupParm.getValue())) {
resultList.add(o);
}
}//类似c++中的仿函数,函数对象
Function<Object, String> extract = s ->
{
try {
Field f = s.getClass().getDeclaredField(groupParm.getAttribute());
f.setAccessible(true);
return String.valueOf(f.get(s));
} catch (NoSuchFieldException | IllegalAccessException e) {
e.printStackTrace();
}
return null;
};
//分组
Map<String, List<Object>> groupResults =
detailList.stream().collect(Collectors.groupingBy(extract));java collection的流的收集器
(多表查询)
SELECT
s.id sid,
s.name,
s.gender,
s.score,
c.id cid,
c.name cname
FROM students s, classes c
WHERE s.gender = 'M' AND c.id = 1;结果集是目标表的行数乘积,对两个各自有100行记录的表进行笛卡尔查询将返回1万条记录,对两个各自有1万行记录的表进行笛卡尔查询将返回1亿条记录。
(列连接 相加)
UNION 和 UNION ALL 关键字都是将两个结果集合并为一个,但这两者从使用和效率上来说都有所不同。
对重复结果的处理:UNION 在进行表链接后会筛选掉重复的记录,Union All 不会去除重复记录。
对排序的处理:Union 将会按照字段的顺序进行排序;UNION ALL 只是简单的将两个结果合并后就返回。当然了只有一列的时候,union才会自动排序,多列的时候两者一样
UNION ALL
如果 union all每一个子句中有排序,需要加limit。
外部排序则正常
(select user_id,user_nickname,user_status from yy_user where user_status = 1)
UNION ALL
(select user_id,user_nickname,user_status from yy_user where user_id > 3)
order by user_id desc
等价于,只能有一个结尾排序,表示先连接后排
select user_id,user_nickname,user_status from yy_user where user_status = 1
UNION ALL
select user_id,user_nickname,user_status from yy_user where user_id > 3
order by user_id desc或者创建中间表
SELECT id,username,mobile,time,leader
FROM (SELECT `id`,`username`,`mobile`,`time`,id AS leader
FROM `grouporder_leader` WHERE `courseid` = 21 AND `merchid` = 23 AND `status` = 1
UNION ALL
SELECT leadorderid,username,mobile,time,null
FROM `grouporder_partner` WHERE courseid=21 and status=1 and merchid=23
)
ORDER BY time DESC数据库三范式是什么?
-
第一范式(1NF):字段具有原子性,不可再分。(所有关系型数据库系统都满足第一范式数据库表中的字段都是单一属性的,不可再分)
-
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。要求数据库表中的每个实例或行必须可以被惟一地区分。通常需要为表加上一个列,以存储各个实例的唯一标识。这个唯一属性列被称为主关键字或主键。
-
满足第三范式(3NF)必须先满足第二范式(2NF)。简而言之,第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。
所以第三范式具有如下特征:
每一列只有一个值,原子性,json违反了
每一行都能区分,主键
每一个表都不包含其他表已经包含的非主关键字信息。非冗余
范式核心是字段含义清楚,消除冗余。反范式,
索引的工作机制是什么?
数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据。索引的实现通常使用 B 树及其变种 B+树
(延伸,b树和b+树)
MySQL的基础操作命令
-
MySQL 是否处于运行状态:ubuntu上运行命令 service mysql status,在 RedHat 上运行命令 service mysqld status
-
开启或停止 MySQL 服务 :运行命令 service mysqld start 开启服务;运行命令 service mysqld stop 停止服务
-
Shell 登入 MySQL: 运行命令 mysql -u root -p
-
列出所有数据库:运行命令 show databases;
-
切换到某个数据库并在上面工作:运行命令 use databasename; 进入名为 databasename 的数据库
-
列出某个数据库内所有表: show tables;
-
获取表内所有 Field 对象的名称和类型 :describe table_name;
(延伸:service与systemctl)
systemctl命令是系统服务管理器指令,它实际上将 service 和 chkconfig 这两个命令组合到一起。
使用service启动服务实际上也是调用systemctl命令。
Systemd是一个系统管理守护进程、工具和库的集合,用于取代System V初始进程。Systemd的功能是用于集中管理和配置类UNIX系统。
(延伸:linux种类)
| 版本名 | 简介 |
|---|---|
| Red Hat Enterprise Linux(RHEL) | Red Hat公司的商业化发行版,稳定受支持。 |
| Fedora | Red Hat公司的免费版本,RHEL的试验场 |
| Community Enterprise Operating System(CentOS)社区企业操作系统 | 源于RHEL依照开放源代码协议(大部分是GPL开源协议)规定释出的源码所编译而成 |
| Debian | 所有的组成部分都是自由软件,完全由网络上的Linux爱好者负责维护 |
| Ubuntu | 派生自Debian,自带图形界面 |
innodb与myisam 的区别?
| innodb | myisam |
|---|---|
| 提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。 | 强调的是性能,每次查询具有原子性,其执行数度比 InnoDB 类型更快,但是不提供事务支持。 |
| 行级锁 | 表级锁 |
| 外键 | 不支持 |
| 支持 MVCC | 不支持 |
| 不支持全文索引 | 支持 |
| 所有的表都保存在同一个数据文件中(也可能是多个文件,或者是独立的表空间文件),InnoDB 表的大小只受限于操作系统文件的大小,一般为 2GB。免费的方案可以是拷贝数据文件、备份binlog,或者用 mysqldump,在数据量达到几十 G 的时候就相对痛苦了 | 每个 MyISAM 在磁盘上存储成三个文件。第一个文件的名字以表的名字开始,扩展名指出文件类型。.frm 文件存储表定义。数据文件的扩展名为.MYD (MYData)。索引文件的扩展名是.MYI (MYIndex)。 在备份和恢复时可单独针对某个表进行操作 |
| 如果没有设定主键或者非空唯一索引,就会自动生成一个 6 字节的主键(用户不可见),数据是主索引的一部分,附加索引保存的是主索引的值。 | 允许没有任何索引和主键的表存在,索引都是保存行的地址 |
SELECT * 和SELECT 全部字段 的 2 种写法有何优缺点?
-
前者要解析数据字典,后者不需要
-
结果输出顺序,前者与建表列顺序相同,后者按指定字段顺序。
-
表字段改名,前者不需要修改,后者需要改
-
后者可以建立组合索引进行优化,前者需要回表
-
后者的可读性比前者要高
group by
group by 一般和聚合函数一起使用才有意义,比如 count sum avg等
出现在select后面的字段 要么是是聚合函数中的,要么就是group by 中的.
HAVNG 子句 和 WHERE 的异同点?
having字句可以让我们筛选成组后的各种数据,where字句在聚合前先筛选记录,也就是说作用在group by和having字句前。而 having子句在聚合后对组记录进行筛选
-
语法上:where 用表中列名,having 用 select 结果别名
-
影响结果范围:where 从表读出数据的行数,having 返回客户端的行数
-
索引:where 可以使用索引,having 不能使用索引,只能在临时结果集操作
-
where 后面不能使用聚集函数,having 是专门使用聚集函数的。
聚集函数也叫列函数,它们都是基于已确定的行集合进行计算的,而where子句则是对数据行进行过滤的,用来确定要哪些行。如果直接用聚集函数,相当于默认选定全部行。
另外,对于having子句再多说一点:没有使用group by而直接使用having子句的例子是不太多见,因为如果没有group by,那么整个结果集就是一个分组,但是这种例子也不是没有,比如当我们需要对“现有的”整个结果集进行“二次筛选”时,就会直接使用having子句了。例如:
查询一个Forum(论坛)最新的Post的SQL为:
select p.* from Forum f left join Thread t on f.id = t.forumId left join Post p on t.id = p.threadId where f.id = 2 having max(p.creationTime);
当记录不存在时 insert,当记录存在时 update,语句怎么写?
假设a是主键
INSERT INTO table (a,b,c) VALUES (1,2,3) ON DUPLICATE KEY UPDATE c=c+1;insert 和 update 的 select 语句语法
INSERT INTO SELECT 语句从一个表复制数据,然后把数据插入到一个已存在的表中。
insert into student (stuid,stuname,deptid) select 10,'xzm',3 from student where stuid > 8;
update (student a inner join student b on b.stuID=10) set a.stuname=concat(b.stuname, b.stuID) where a.stuID=10;若一张表中只有一个字段 VARCHAR(N)类型,utf8 编码,则 N 最大值为多少(精确到数量级即可)?
由于 utf8 的每个字符最多占用 3 个字节。而 MySQL 定义行的长度不能超过65535,因此 N 的最大值计算方法为:(65535-1-2)/3。减去 1 的原因是实际存储从第二个字节开始,减去 2 的原因是因为要在列表长度存储实际的字符长度,除以 3 是因为 utf8 限制:每个字符最多占用 3 个字节。
varchar 与 char 的区别
varchar 与 char 的区别: char 是一种固定长度的类型,varchar 则是一种可变长度的类型.
varchar(50)中 50 的涵义 : 最多存放 50 个字节
以及 int(20)中的 20 的涵义
int(20)中 20 的涵义: int(M)中的 M indicates the maximum display width (最大显示宽度)for integer types. The maximum legal display width is 255.
这个长度是为了告诉MYSQL我们这个字段的存储的数据的宽度为5位数,少于M位前面自动补0,多于M位但只要是int的表示范围也能正常存储。可以设置为int(11)
设计表
理清实体
第一:首先要考虑的是咱们这个数据库的主要作用是什么?至少包含哪些数据?这些数据又分别属于那些实体对象?对象之间又存在什么样的关系?比如说新闻文章管理系统的数据库,它要存放的数据至少包括:文章分类,文章标题,发文时间,作者;而既然是管理系统,那么肯定会有人要添加删除修改文章,那么就延伸出需要管理员,有管理员了就存在账号,密码;如果还要有对文章的评论功能,那就还有评论的标题,评论的类容,评论人姓名,评论时间等。这么多需要存放的数据,如何归类,归类后又如何整理相互之间的关系呢?这就需要用到工具。
E-R(Entity-relationship) 模型,建立E-R模型的工具很多,甚至纸笔也算是一种工具。而E-R图的画法其实也很多。它的主要作用是将所有要存入数据库的数据归类、整理成一个个的分类,这个分类被称之为实体,而被归如这个分类的数据则被称之为实体的属性。不同的实体之间存在关联,比如文章和管理员之间就存在谁发布了文章,文章和评论之间存在某条评论是属于那篇文章,这样的关系,在E-R模型上就必须把这些体现出来。具体E-R的工具和画法稍后有一小节来讲,这里先不赘述。
属性用什么样的数据类型
每一个实体就是一个表,而实体的属性就是这个表的列,那么现在问题就出来了,到底什么样的列该用什么样的数据类型,比如文章的标题该用什么数据类型呢?
小天:NCHAR(50)行不?因为我们这边是采用Unicode字符,而文章标题字符串,50个字足够了。
接着来看你用的NCHAR(50)有不有问题,首先我们说什么情况下用NCHAR类型呢?一是在Unicode字符的时候用N开头的类型,其次只有在数据长度基本差不多的情况采用。但是文章的标题会每一个都固定长度吗?而且char类型最致命的一个缺陷是,只要用它的数据,只要长度不够,就自动填充空格,问题出来,如果连续10万行数据的这一列都只有40个字符,那么每行都增加10个空格,这样下来10万*10字符的空间实际上就白白的被占用了。虽然有人说现在磁盘成本已经越来越廉价,但是我觉得吧,这不是钱的问题,因为数据库体积越大,处理数据的效率必然受影响。再比如说,用户注册中年龄的问题,肯定首选tinyint,因为目前人类的年龄不可能超过255岁,而这个类型只占1字节的空间,如果习惯性的用int类型,咋一看也没有问题,可惜就白白浪费了3字节的空间,因为int是4字节的长度。
要做到哪怕一字节的空间也不能浪费,但是也不能节约得整个数据库都不好用了。
char varchar
存放一个字符
在内存中不一样,在磁盘中一样
默认值
尽量少用允许为空,可以用默认值,如果一定要允许也尽量将之靠后。
空值既不是0也不是空字符,而表示未知,用null表示。这就有问题了,首先如果处在变长类型列中的null值本身虽然不占空间,但是它所在列确实实实在在的要占用空间的。
再则null比较特殊,数据库要对null字段进行额外的操作,所以如果表中有较多的null字段时会影响数据库的性能。还有一点是null字段会给我们编程带来一些不大不小的麻烦,比如制造一些bug。
小天:我要是做个会员管理系统,除了会员账号、密码、电子邮箱之外的资料我觉得都可以为空,但是总不可能数据库就只有这三个字段撒。
老田:当然不可能这么少啦,但是为什么不可以做成两张表,一张为基本信息表 一张详细信息表。将用户可能一般都不填写的资料单独放在详细资料表,那么如果用户不填写详细资料,这个表里就少一行数据。
小天:这个主意不错哦,我还有个问题,就是用户注册时间的问题,我肯定希望记录下用户是什么时候注册的,但是这行人家用户不可能愿意写,就算写也可能乱写,咋办?
老田:这个简单,用默认值。比如要解决注册日期的问题就在用户基本信息表中加一列注册日期(不要用中文),给这一列设置默认值“GETDATE()”,然后每次添加信息的时候就不去管这一列了,反正它会在执行插入数据的时候把系统当前最新时间加入当前行。
主键
主键的问题,来看个实际的例子。公安部要通缉孙悟空,这问题就出来了,全国叫孙悟空的人可能不只一猴,所以单纯靠名字是不能通缉的。长相?不行,全国的猴子多了去了,长得像的也挺多。我们这里不是YY小说,不玩灵魂气息。哪咋办呢,就是给全国的猴子办身份证,每个身份证上的编号绝对不能相同。于是以后再要通缉孙悟空的话,就好办了。我们的数据表中数据也一样,每一行都需要一个绝不重复的标志作为主键。
小天:你这意思就是每张表都需要一个主键?我的会员管理系统中难道也让人家注册的时候填写身份证号?
老田:让人注册的时候写身份证号一般来说是不现实的,咋办呢?就只好我们额外的加上一行作为主键了,这也是在数据库中常见的做法,为表增加一行看起来风马牛不相及的行,作用只有一个,就是做标志主键。
取值的约束和规则
约束和规则,用于确保数据完整有效性,一旦定义了约束和规则,那么只有满足这些条件的数据才可一倍插入数据库。比如要求注册会员的性别要么是男,要么是女,绝对不允许第三种情况,再比如年龄只能是18-80岁,其他注册不了。
外键关系,比如会员管理系统,如果所有会员都是同样当然无所谓,但如果分为普通会员,金、银、铜牌会员几种类型,这时候就需要好好的思量下了。到底是在会员信息表中增加一个列来存储会员类型的名称呢还是单独用另外一张表来存储会员名称,再把两张表关联起来。如下处理方式
第一种方式
| 主键 | 登录名 | 密码 | 会员类型 | 注册日期 |
|---|---|---|---|---|
| 1 | Thc | 123456 | 金牌会员 | 2009-10-21 |
| 2 | Abc | 123456 | 银牌会员 | 2009-10-22 |
| 3 | Cda | 123456 | 普通会员 | 2009-10-20 |
第二种方式,两张表
| 主键 | 登录名 | 密码 | 会员类型 | 注册日期 |
|---|---|---|---|---|
| 1 | Thc | 123456 | 1 | 2009-10-21 |
| 2 | Abc | 123456 | 2 | 2009-10-22 |
| 3 | Cda | 123456 | 3 | 2009-10-20 |
| 主键 | 会员类型 |
|---|---|
| 1 | 金牌会员 |
| 2 | 银牌会员 |
| 3 | 普通会员 |
第二种方式中会员信息表中的会员类型列就是外键。这样做很明显就违背了本章最开始说的表要尽量少这个宗旨。可有时候是有必要的,还是以会员中心这个案例来说,我还是选择用第二种方式。假设会员类型分类可能随着时间的过去,企业的发展,会员会有很多,那么这个会员类型列因为只存储一个int类型的字段,所以空间就节约出很多来。
另外一些原因就是考虑到方便编程和程序的扩展,比如增加新的会员类型分类等等。
索引
考虑是否使用索引,索引也是一种数据库对象,是加快对数据表中数据检索的一种手段,是提高数据库使用效率的一种重要方法。于是要在那些列上使用索引,对那些列不使用索引,是使用聚簇索引还是使用费聚簇索引,是否使用全文索引,等等,很多问题需要认真的去思考。
大字段以读为主,拆表
表中有大字段 X(例如:text 类型),且字段 X 不会经常更新,以读为为主,将该字段拆成子表好处是什么
如果字段里面有大字段(text,blob)类型的,而且这些字段的访问并不多,这时候放在一起就变成缺点了。 MYSQL 数据库的记录存储是按行存储的,数据块大小又是固定的(16K),每条记录越小,相同的块存储的记录就越多。此时应该把大字段拆走,这样应付大部分小字段的查询时,就能提高效率。当需要查询大字段时,此时的关联查询是不可避免的,但也是值得的。拆分开后,对字段的 UPDAE 就要 UPDATE 多个表了
数据库瓶颈,性能调优
不管是IO瓶颈,还是CPU瓶颈,最终都会导致数据库的活跃连接数增加,进而逼近甚至达到数据库可承载活跃连接数的阈值。在业务Service来看就是,可用数据库连接少甚至无连接可用。接下来就可以想象了吧(并发量、吞吐量、崩溃)。
1、IO瓶颈
第一种:磁盘读IO瓶颈,热点数据太多,数据库缓存放不下,每次查询时会产生大量的IO,降低查询速度 -> 分库和垂直分表。
第二种:网络IO瓶颈,请求的数据太多,网络带宽不够 -> 分库。
第三种:内存,内存一般不是瓶颈。
2、CPU瓶颈
第一种:SQL问题,如SQL中包含join,group by,order by,非索引字段条件查询等,增加CPU运算的操作 -> SQL优化,建立合适的索引,在业务Service层进行业务计算。
第二种:单表数据量太大,查询时扫描的行太多,SQL效率低,CPU率先出现瓶颈 -> 水平分表。
第三种:并发量过高->分库
客户端连接池数量设置为多少合适?
Oracle 性能小组做过测试。
模拟 9600 个并发线程来操作数据库,每两次数据库操作之间 sleep 550ms,数据库连接池大小为 2048。
每个请求要在连接池队列里等待 33ms,获得连接之后,执行SQL需要耗时77ms, CPU 消耗维持在 95% 左右
设置成 1024,其他测试参数不变,获取连接等待时长基本不变,但是 SQL 的执行耗时降低。
连接池的大小降低到 96,每个请求在连接池队列中的平均等待时间为 1ms, SQL 执行耗时为 2ms。
可以说什么都没做,就从100ms降到了3ms,数量级的优化。
为什么?Nginx 也是内部仅仅使用了 4 个线程,其性能就大大超越了 100 个进程的 Apache HTTPD。
cpu调度的问题,一个核只能跑一个线程性能最高,如果同时跑多个,涉及到上下文切换。
连接数 = ((核心数 * 2) + 有效磁盘数) 主要是从cpu核数角度考虑,我们再考虑上磁盘io,假如是机械硬盘,io较慢,那么一个连接就需要在磁盘io上等待更多的时间,此时可以稍微加大线程数,多线程很适合io密集型。如果是固态,那么io快,io延迟低,就无需过多考虑磁盘io,连接数,越接近核心数越好。
实际上,连接池的大小的设置还是要结合实际的业务场景来说事,不是死板的公式。
比如说,系统同时混合了长事务和短事务,就不能单纯用一个连接池了。正确的做法应该是创建两个连接池,一个服务于长事务,一个服务于"实时"查询,也就是短事务。
分库
主要解决的是并发量大的问题
按照业务边界,把各个业务的数据从一个单一的数据库中拆分开,分表把订单、物流、商品、会员等单独放到单独的数据库中。当你的数据库的读或者写的QPS过高,导致你的数据库连接数不足了的时候,就需要考虑分库了,通过增加数据库实例的方式来提供更多的可用数据库链接,从而提升系统的并发度。
分表
主要解决的是数据量大的问题。
假如你的单表数据量非常大,因为并发不高,数据量连接可能还够,但是存储和查询的性能遇到了瓶颈了,做了很多优化之后还是无法提升效率的时候,就需要考虑做分表了。
通过将数据拆分到多张表中,来减少单表的数据量,从而提升查询速度。
一般我们认为,单表行数超过 500 万行或者单表容量超过 2GB之后,才需要考虑做分库分表了,小于这个数据量,遇到性能问题先建议大家通过其他优化来解决。
如何选分表字段-以电商为例
在分库分表的过程中,我们需要有一个字段用来进行分表,比如按照用户分表、按照时间分表、按照地区分表。这里面的用户、时间、地区就是所谓的分表字段。
那么,在选择这个分表字段的时候,一定要注意,要根据实际的业务情况来做慎重的选择。
比如说我们要对交易订单进行分表的时候,我们可以选择的信息有很多,比如买家Id、卖家Id、订单号、时间、地区等等,具体应该如何选择呢?
通常,如果有特殊的诉求,比如按照月度汇总、地区汇总等以外,我们通常建议大家按照买家Id进行分表。因为这样可以避免一个关键的问题那就是——数据倾斜(热点数据)。
买家还是卖家?
首先,我们先说为什么不按照卖家分表?
因为我们知道,电商网站上面是有很多买家和卖家的,但是,一个大的卖家可能会产生很多订单,比如像苏宁易购、当当等这种店铺,他每天在天猫产生的订单量就非常的大。如果按照卖家Id分表的话,那同一个卖家的很多订单都会分到同一张表。
那就会使得有一些表的数据量非常的大,但是有些表的数据量又很小,这就是发生了数据倾斜。这个卖家的数据就变成了热点数据,随着时间的增长,就会使得这个卖家的所有操作都变得异常缓慢。
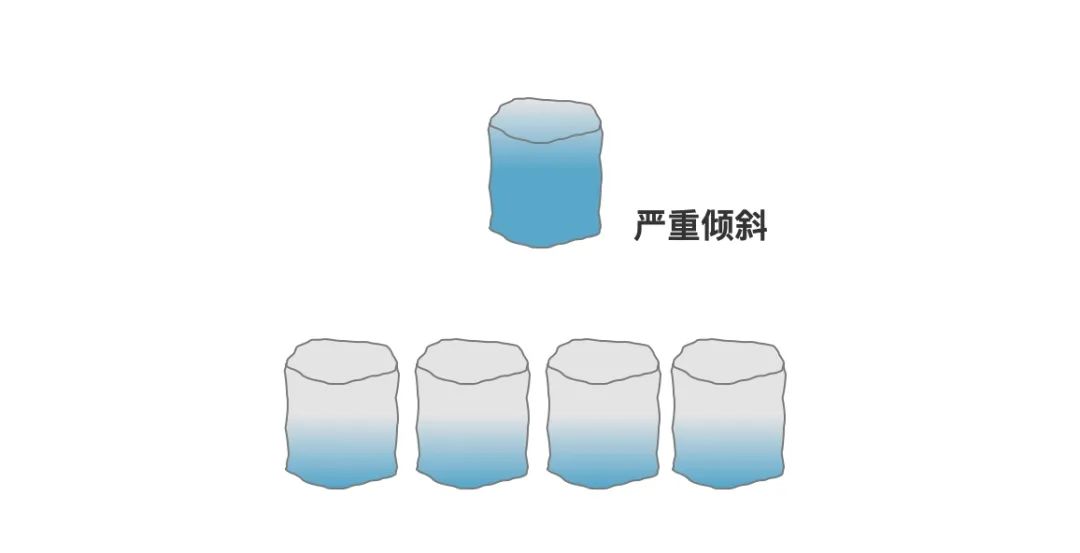
但是,买家ID做分表字段就不会出现这类问题,因为一个不太容易出现一个买家能把数据买倾斜了。
但是需要注意的是,我们说按照买家Id做分表,保证的是同一个买家的所有订单都在同一张表 ,并不是要给每个买家都单独分配一张表。
我们在做分表路由的时候,是可以设定一定的规则的,比如我们想要分1024张表,那么我们可以用买家ID或者买家ID的hashcode对1024取模,结果是0000-1023,那么就存储到对应的编号的分表中就行了。
卖家查询怎么办?
如果按照买家Id进行了分表,那卖家的查询怎么办,这不就意味着要跨表查询了吗?
首先,业务问题我们要建立在业务背景下讨论。电商网站订单查询有几种场景?
1、买家查自己的订单
2、卖家查自己的订单
3、平台的小二查用户的订单。
首先,我们用买家ID做了分表,那么买家来查询的时候,是一定可以把买家ID带过来的,我们直接去对应的表里面查询就行了。
那如果是卖家查呢?卖家查询的话,同样可以带卖家id过来,那么,我们可以有一个基于binlog、flink等准实时的同步一张卖家维度的分表,这张表只用来查询,来解决卖家查询的问题。

本质上就是用空间换时间的做法。
不知道大家看到这里会不会有这样的疑问:同步一张卖家表,这不又带来了大卖家的热点问题了吗?
首先,我们说同步一张卖家维度的表来,但是其实所有的写操作还是要写到买家表的,只不过需要准实时同步的方案同步到卖家表中。也就是说,我们的这个卖家表理论上是没有业务的写操作,只有读操作的。
所以,这个卖家库只需要有高性能的读就行了,那这样的话就可以有很多选择了,比如可以部署到一些配置不用那么高的机器、或者其实可以干脆就不用MYSQL,而是采用HBASE、PolarDB、Lindorm等数据库就可以了。这些数据库都是可以海量数据,并提供高性能查询的。
还有呢就是,大卖家一般都是可以识别的,提前针对大卖家,把他的订单,再按照一定的规则拆分到多张表中。因为只有读,没有写操作,所以拆分多张表也不用考虑事务的问题。
按照订单查询怎么办?
上面说的都是有买卖家ID的情况,那没有买卖家ID呢?用订单号直接查怎么办呢?
这种问题的解决方案是,在生成订单号的时候,我们一般会把分表解决编码到订单号中去,因为订单生成的时候是一定可以知道买家ID的,那么我们就把买家ID的路由结果比如1023,作为一段固定的值放到订单号中就行了。这就是所谓的"基因法"
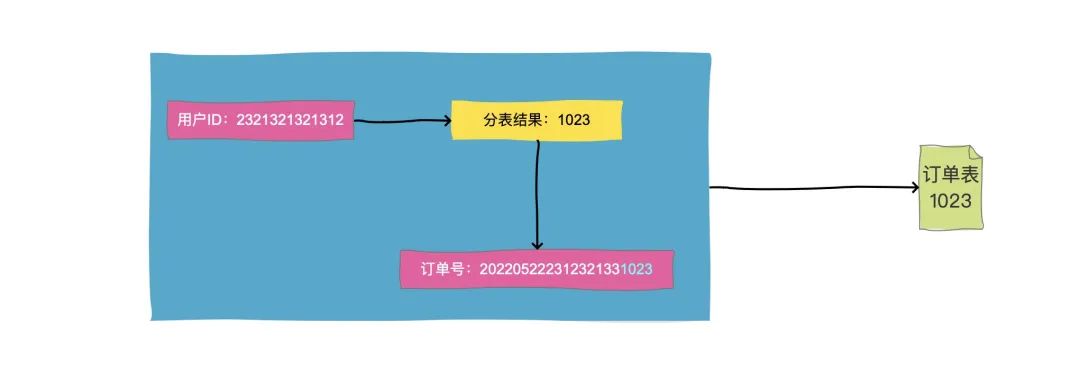
这样按照订单号查询的时候,解析出这段数字,直接去对应分表查询就好了。
至于还有人问其他的查询,没有买卖家ID,也没订单号的,那其实就属于是低频查询或者非核心功能查询了,那就可以用ES等搜索引擎的方案来解决了。就不赘述了。
分表算法
直接取模
在分库分表时,我们是事先可以知道要分成多少个库和多少张表的,所以,比较简单的就是取模的方式。
比如我们要分成128张表的话,就用一个整数来对128取模就行了,得到的结果如果是0002,那么就把数据放到order_0002这张表中。
HashCode取模
那如果分表字段不是数字类型,而是字符串类型怎么办呢?有一个办法就是哈希取模,就是先对这个分表字段取HashCode,然后在再取模。
但是需要注意的是,Java中的hash方法得到的结果有可能是负数,需要考虑这种负数的情况。
一致性Hash
前面两种取模方式都比较不错,可以使我们的数据比较均匀的分布到多张分表中。但是还是存在一个缺点。
那就是如果需要扩容二次分表,表的总数量发生变化时,就需要重新计算hash值,就需要涉及到数据迁移了。
为了解决扩容的问题,我们可以采用一致性哈希的方式来做分表。
全局ID的生成
涉及到分库分表,就会引申出分布式系统中唯一主键ID的生成问题,因为在单表中我们可以用数据库主键来做唯一ID,但是如果做了分库分表,多张单表中的自增主键就一定会发生冲突。那就不具备全局唯一性了。
那么,如何生成一个全局唯一的ID呢?有以下几种方式:
UUID
很多人对UUID都不陌生,它是可以做到全局唯一的,而且生成方式也简单,但是我们通常不推荐使用他做唯一ID,首先UUID太长了,其次字符串的查询效率也比较慢,而且没有业务含义,根本看不懂。
基于某个单表做自增主键
多张单表生成的自增主键会冲突,但是如果所有的表中的主键都从同一张表生成是不是就可以了。
所有的表在需要主键的时候,都到这张表中获取一个自增的ID。
这样做是可以做到唯一,也能实现自增,但是问题是这个单表就变成整个系统的瓶颈,而且也存在单点问题,一旦他挂了,那整个数据库就都无法写入了。
基于多个单表+步长做自增主键
为了解决单个数据库做自曾主键的瓶颈及单点故障问题,我们可以引入多个表来一起生成就行了。
但是如何保证多张表里面生成的Id不重复呢?如果我们能实现以下的生成方式就行了:
实例1生成的ID从1000开始,到1999结束。
实例2生成的ID从2000开始,到2999结束。
实例3生成的ID从3000开始,到3999结束。
实例4生成的ID从4000开始,到4999结束。
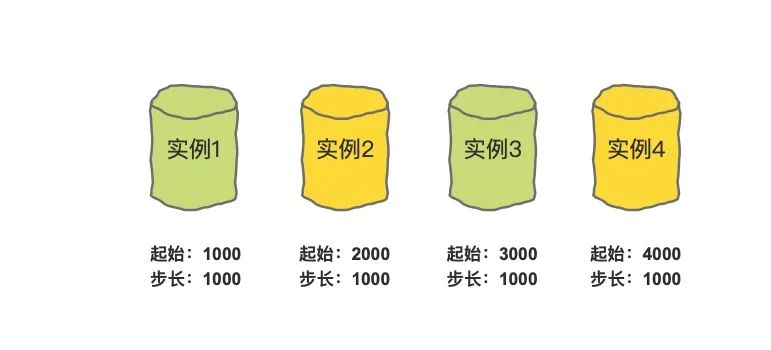
这样就能避免ID重复了,那如果第一个实例的ID已经用到1999了怎么办?那就生成一个新的起始值:
实例1生成的ID从5000开始,到5999结束。
实例2生成的ID从6000开始,到6999结束。
实例3生成的ID从7000开始,到7999结束。
实例4生成的ID从8000开始,到8999结束。
我们把步长设置为1000,确保每一个单表中的主键起始值都不一样,并且比当前的最大值相差1000就行了。
雪花算法
雪花算法也是比较常用的一种分布式ID的生成方式,它具有全局唯一、递增、高可用的特点。
雪花算法生成的主键主要由 4 部分组成,1bit符号位、41bit时间戳位、10bit工作进程位以及 12bit 序列号位。
时间戳占用41bit,精确到毫秒,总共可以容纳约69年的时间。
工作进程位占用10bit,其中高位5bit是数据中心ID,低位5bit是工作节点ID,做多可以容纳1024个节点。
序列号占用12bit,每个节点每毫秒0开始不断累加,最多可以累加到4095,一共可以产生4096个ID。
所以,一个雪花算法可以在同一毫秒内最多可以生成1024 X 4096 = 4194304个唯一的ID
控制内存分配的全局参数
innodb bufferpool_size > 表示缓冲池字节大小,InnoDB 缓存表和索引数据的内存区域。mysql 默认的值是 128M。最大值与你的CPU 体系结构有关,在 32 位操作系统,最大值是 4294967295(2^32-1) ,在 64 位操作系统,最大值为18446744073709551615 (2^64-1)。 > 在 32 位操作系统中,CPU 和操作系统实用的最大大小低于设置的最大值。如果设定的缓冲池的大小大于 1G,设置 innodbbufferpoolinstances 的值大于 1. >
数据读写在内存中非常快, innodbbufferpoolsize 减少了对磁盘的读写。 当数据提交或满足检查点条件后才一次性将内存数据刷新到磁盘中。然而内存还有操作系统或数据库其他进程使用, 一般设置 bufferpool 大小为总内存的 3/4 至 4/5。 若设置不当, 内存使用可能浪费或者使用过多。 对于繁忙的服务器, buffer pool 将划分为多个实例以提高系统并发性, 减少线程间读写缓存的争用。buffer pool 的大小首先受 innodbbufferpool_instances 影响, 当然影响较小。
query cachesize > 当 mysql 接收到一条 select 类型的 query时,mysql 会对这条 query 进行 hash 计算而得到一个 hash 值,然后通过该 hash 值到 query cache 中去匹配,如果没有匹配中,则将这个hash 值存放在一个 hash 链表中,同时将 query 的结果集存放进cache 中,存放 hash 值的链表的每一个 hash 节点存放了相应 query结果集在 cache 中的地址,以及该 query 所涉及到的一些 table 的相关信息;如果通过 hash 值匹配到了一样的 query,则直接将 cache 中相应的 query 结果集返回给客户端。如果 mysql 任何一个表中的任何一条数据发生了变化,便会通知 query cache 需要与该 table 相关的query 的 cache 全部失效,并释放占用的内存地址。
优缺点 >> 1. query 语句的 hash 计算和 hash 查找带来的资源消耗。mysql 会对每条接收到的 select 类型的 query 进行 hash 计算然后查找该 query 的 cache 是否存在,虽然 hash 计算和查找的效率已经足够高了,一条 query 所带来的消耗可以忽略,但一旦涉及到高并发,有成千上万条 query 时,hash 计算和查找所带来的开销就的重视了; >> 2. query cache 的失效问题。如果表变更比较频繁,则会造成 query cache 的失效率非常高。表变更不仅仅指表中的数据发生变化,还包括结构或者索引的任何变化; >> 3. 对于不同 sql 但同一结果集的 query 都会被缓存,这样便会造成内存资源的过渡消耗。sql 的字符大小写、空格或者注释的不同,缓存都是认为是不同的 sql(因为他们的 hash 值会不同); >> 4. 相关参数设置不合理会造成大量内存碎片,相关的参数设置会稍后介绍。
readbuffersize >是 MySQL 读入缓冲区大小。对表进行顺序扫描的请求将分配一个读入缓冲区,MySQL 会为它分配一段内存缓冲区。readbuffersize 变量控制这一缓冲区的大小。如果对表的顺序扫描请求非常频繁,并且你认为频繁扫描进行得太慢,可以通过增加该变量值以及内存缓冲区大小提高其性能。
有哪些数据库优化方面的经验?
1.用 PreparedStatement, 一般来说比 Statement 性能高,安全性好。
简介:
Statement 对象用于将 SQL 语句发送到数据库中。有三种 Statement 对象,它们都作为在给定连接上执行 SQL语句的包容器:Statement、PreparedStatement,和CallableStatement,他们是继承关系。
Statement 对象用于执行不带参数的简单 SQL 语句;PreparedStatement 对象用于执行带或不带参数的预编译 SQL 语句;CallableStatement 对象用于执行对数据库已存储过程的调用。
性能高:
Statement每次执行sql语句,发给服务器的数据库去执行,涉及步骤:语法检查、语义分析, 编译,缓存。
对于仅执行一次查询的情形,效率高于PreparedStatement
但是很多情况,我们的一条sql语句可能会反复执行,或者每次执行的时候只有个别的值不同(比如query的where子句值不同,update的set子句值不同,insert的values值不同)。如果每次重新语法语义检查,编译执行,那么效率就很低了。于是出现了预编译语句,将这类语句中的值用占位符替代,可以视为将sql语句模板化或者说参数化。他只用编译一次、由于采用了Cache机制,则预编译的语句,就会放在Cache中,下次执行相同的SQL语句时,则可以直接从Cache中取出来,指定参数即可运行。就可以多次运行,省去了语法检查,语义分析的过程。
PreparedStatement pstmt = con.prepareStatement("UPDATE EMPLOYEES SET name= ? WHERE ID = ?");
pstmt.setString(1, "李四");
pstmt.setInt(2, 1);
pstmt.executeUpdate();安全性高:
安全性更好,有效防止SQL注入的问题。
(延伸,sql注入,web安全方面)
2.有外键约束会影响插入和删除性能,如果程序能够保证数据的完整性,那在设计数据库时就去掉外键。
3.表中允许适当冗余,查询快
4.UNION ALL 要比 UNION 快很多,所以,如果可以确认合并的两个结果集中不包含重复数据且不需要排序时的话,那么就使用 UNIONALL。
UNION 和 UNION ALL 关键字都是将两个结果集合并为一个,但这两者从使用和效率上来说都有所不同。
- 对重复结果的处理:UNION 在进行表链接后会筛选掉重复的记录,Union All 不会去除重复记录。
- 对排序的处理:Union 将会按照字段的顺序进行排序,如果多字段则和UNION ALL 一样,只是简单的将两个结果合并后就返回。
原理-架构
调优
善用官网文档,很全面https://dev.mysql.com/doc/refman/8.0/en/innodb-buffer-pool.html
架构
mysql是单进程多线程,cs架构
服务层,管理连接,权限验证
存储引擎层,存储数据,提供读写结构
连接,长连接
最大连接数默认151,注意不是连接池的数量
linux单进程8M 8G 1024个*0.8
(延伸,发送失败)从客户端发到服务端,会不会存在校验,失败?发不过去?各种长连接问题
连接池配置。配置的是客户端的连接池,最好接近cpu核数。
缓存
8.0没有缓存,5.7缓存默认关闭,表缓存,表中一条更改全部失效
解析器
词法解析(分词,识别出一个个单词),语法解析(;) 最终生成一个解析树

预处理器
语义解析(判断表是否存在)
最终生成一个新的解析树
优化器optimizer
在索引建立之后,一条语句可能会命中多个索引,这时,索引的选择,就会交由 优化器 来选择合适的索引。
一条语句有多种执行方法(先查表?先查哪一列?逐行比较还是走索引?去除无效的部分),他计算所有的执行方法的cost 相对的值,选择最好的一个。
用explain看是否按照我们所想执行的,可以force index 强制指定某一索引,或者建立一个更适合的索引给优化器选择,也可以重新统计索引信息。还可以考虑修改语句,引导需要期望的结果,比如:order by b limit 1 -> order by b,a limit 1,引导到组合索引上
(延伸)优化器比较索引的依据?
- 扫描的行数(基于采样)。扫描的行数越少,意味着访问磁盘数据的次数越少,消耗的 CPU 资源越少。
- 是否回表操作
- 是否使用临时表
- 是否使用排序
优化器是如何判断扫描行数的?
- MySQL 在真正开始执行语句之前,并不能精确地知道满足这个条件的记录有多少条,而只能根据统计信息来估算记录数。
– 这个统计信息就是索引的“区分度”。
-
显然,一个索引上不同的值越多,这个索引的区分度就越好。
-
而一个索引上不同的值的个数,我们称之为“基数”(cardinality)。
-
也就是说,这个基数越大,索引的区分度越好。
- 可以使用 show index 方法,看到一个索引的基数。
-
- 在使用普通索引,因为都要回表到主键索引上查出整行数据,这个代价优化器也要算进去的。
MySQL 是怎样得到统计信息的呢?
-
-
使用 采样统计
-
原理
-
采样统计的时候,InnoDB 默认会选择 N 个数据页,统计这些页面上的不同值,得到一个平均值,然后乘以这个索引的页面数,就得到了这个索引的基数。
- 而数据表是会持续更新的,索引统计信息也不会固定不变。所以,当变更的数据行数超过 1/M 的时候,会自动触发重新做一次索引统计。
-
– 为什么需要使用 采样统计?
- 因为把整张表取出来一行行统计,虽然可以得到精确的结果,但是代价太高了,所以只能选择“采样统计”。
– 在 MySQL 中,有两种存储索引统计的方式,可以通过设置参数 innodb_stats_persistent 的值来选择:
-
设置为 on 的时候,表示统计信息会持久化存储。这时,默认的 N 是 20,M 是 10。
设置为 off 的时候,表示统计信息只存储在内存中。这时,默认的 N 是 8,M 是 16。
- 由于是采样统计,所以不管 N 是 20 还是 8,这个基数都是很容易不准的。
索引选择异常的问题可以有哪几种处理方式?
– 重新统计索引信息
- 既然是统计信息不对,那就修正。analyze table t 命令,可以用来重新统计索引信息。
– 指定使用索引
- select * from table force index(
index_name);
执行计划
explain mysql会显示一些来自于优化器的关于sql执行计划的信息。比如是否使用了索引
执行器
调用存储引擎实现的接口
磁盘
存储引擎 存储和管理的方式
存储引擎怎么来?5.5.5之后默认innoDB,以前是myisam
创建后能不能修改?可以
不同存储引擎区别?
预读取
局部性的原理,操作系统页4KB,数据页16KB
buffer pool 特殊的lru算法冷热分区
日志系统
server层
binlog
errorlog
slowlog
relaylog
innodb存储引擎
undolog
redolog
redo Log 重做日志-存储引擎层
记录的物理层
innodb_log触发刷脏三种条件, redolog满,buffer满了,1s一次
崩溃恢复。两阶段提交用到这个日志。
undo Log 撤销日志-存储引擎层
记录的物理层。记录了历史修改记录,便于回滚。mvvc用的这个

binlog 服务层
记录的逻辑层,sql语句
记录了ddl(Data Definition Language)dml (Data Manipulation Language)
数据恢复,主从复制通过binlog完成
update语句执行过程
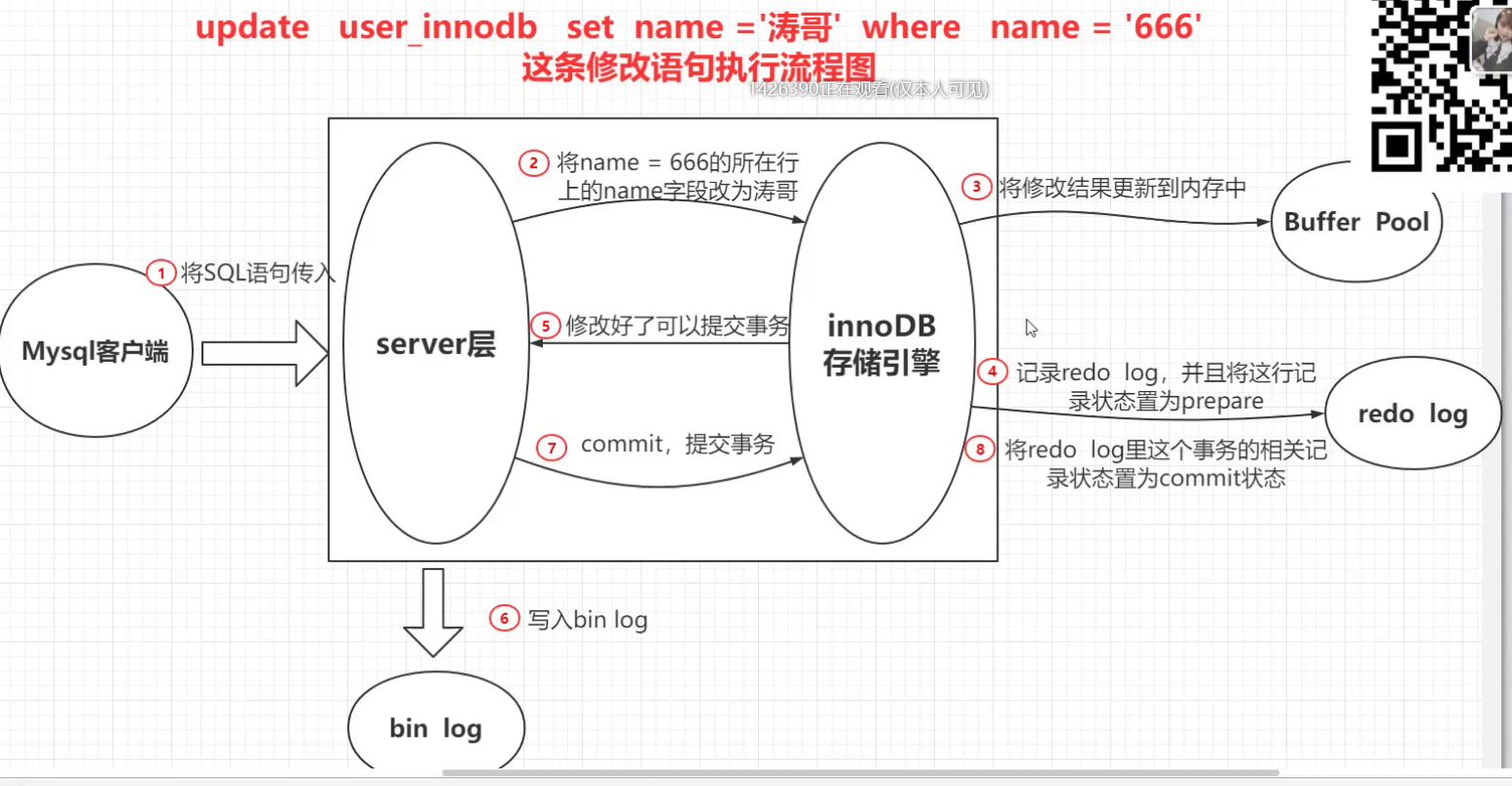
当优化器分析出成本最小的执行计划后,执行器就按照执行计划开始进行更新操作。
具体更新一条记录 UPDATE t_user SET name = 'xiaolin' WHERE id = 1; 的流程如下:
- 执行器负责具体执行,会调用存储引擎的接口,通过主键索引树搜索获取 id = 1 这一行记录:
- 如果 id=1 这一行所在的数据页本来就在 buffer pool 中,就直接返回给执行器更新;
- 如果记录不在 buffer pool,将数据页从磁盘读入到 buffer pool,返回记录给执行器。
- 执行器得到聚簇索引记录后,会看一下更新前的记录和更新后的记录是否一样:
- 如果一样的话就不进行后续更新流程;
- 如果不一样的话就把更新前的记录和更新后的记录都当作参数传给 InnoDB 层,让 InnoDB 真正的执行更新记录的操作;
- 开启事务, InnoDB 层更新记录前,首先要记录相应的 undo log,因为这是更新操作,需要把被更新的列的旧值记下来,也就是要生成一条 undo log,undo log 会写入 Buffer Pool 中的 Undo 页面,不过在内存修改该 Undo 页面后,需要记录对应的 redo log。
- InnoDB 层开始更新记录,会先更新内存(同时标记为脏页),然后将记录写到 redo log 里面,这个时候更新就算完成了。为了减少磁盘I/O,不会立即将脏页写入磁盘,后续由后台线程选择一个合适的时机将脏页写入到磁盘。这就是 WAL 技术,MySQL 的写操作并不是立刻写到磁盘上,而是先写 redo 日志,然后在合适的时间再将修改的行数据写到磁盘上。
- 至此,一条记录更新完了。
- 在一条更新语句执行完成后,然后开始记录该语句对应的 binlog,此时记录的 binlog 会被保存到 binlog cache,并没有刷新到硬盘上的 binlog 文件,在事务提交时才会统一将该事务运行过程中的所有 binlog 刷新到硬盘。
- 事务提交(为了方便说明,这里不说组提交的过程,只说两阶段提交):
- prepare 阶段:将 redo log 对应的事务状态设置为 prepare,然后将 redo log 刷新到硬盘;
- commit 阶段:将 binlog 刷新到磁盘,接着调用引擎的提交事务接口,将 redo log 状态设置为 commit(将事务设置为 commit 状态后,刷入到磁盘 redo log 文件);
- 至此,一条更新语句执行完成。
事务提交时的问题。
事务提交后,redo log 和 binlog 都要持久化到磁盘,但是这两个是独立的逻辑,可能出现半成功的状态,这样就造成两份日志之间的逻辑不一致。并且会导致在主从复制的时候出现数据不一致的问题。因此两阶段提交。
两阶段提交还是有问题。
- 磁盘 I/O 次数高:对于“双1”配置,每个事务提交都会进行两次 fsync(刷盘),一次是 redo log 刷盘,另一次是 binlog 刷盘。
- 锁竞争激烈:两阶段提交虽然能够保证「单事务」两个日志的内容一致,但在「多事务」的情况下,却不能保证两者的提交顺序一致,因此,在两阶段提交的流程基础上,还需要加一个锁来保证提交的原子性,从而保证多事务的情况下,两个日志的提交顺序一致。解决:组提交。
原理-索引
索引种类
-
普通索引: 即针对数据库表创建索引
-
唯一索引: 与普通索引类似,不同的就是:MySQL 数据库索引列的值必须唯一,但允许有空值
-
主键索引: 它是一种特殊的唯一索引,不允许有空值。一般是在建表的时候同时创建主键索引
-
组合索引: 为了进一步提高 MySQL 的效率,就要考虑建立组合索引。即将数据库表中的多个字段联合起来作为一个组合索引。
MySQL主要提供2种方式的索引:B+Tree索引,Hash索引
B树索引具有范围查找和前缀查找的能力,对于有N节点的n路B树,检索一条记录的复杂度为O(lognN)。
哈希索引只能做等于查找,但是无论多大的Hash表,查找复杂度都是O(1)。
显然,如果值的差异性大,并且以等值查找(=,in)为主,Hash索引是更高效的选择,它有O(1)的查找复杂度。
如果值的差异性相对较差,并且以范围查找为主,B树是更好的选择,它支持范围查找。
索引的格式
key 哪一个文件,偏移量,占用的空间 hive是这样
索引是K-V格式

为什么不用hash?范围查询怎么办?
bst树 avl树 都是二路搜索树,层数过多。
b树 非叶子节点就存放了数据,导致一个节点放的指针少,进而使得层数增多,且也不支持范围查询。
b+树,只有叶子结点放了数据,并且所有叶子结点是串起来的。即b+树有两个头指针,一个指向根节点,一个指向关键字最小的叶子节点,所有叶子节点形成了一个循环链表。
磁盘预读,操作系统从磁盘中取数据的最小单位:页 datapage 硬盘一般是4K,也就是8个扇区。 innodb管理的单位则是16kB。
B树
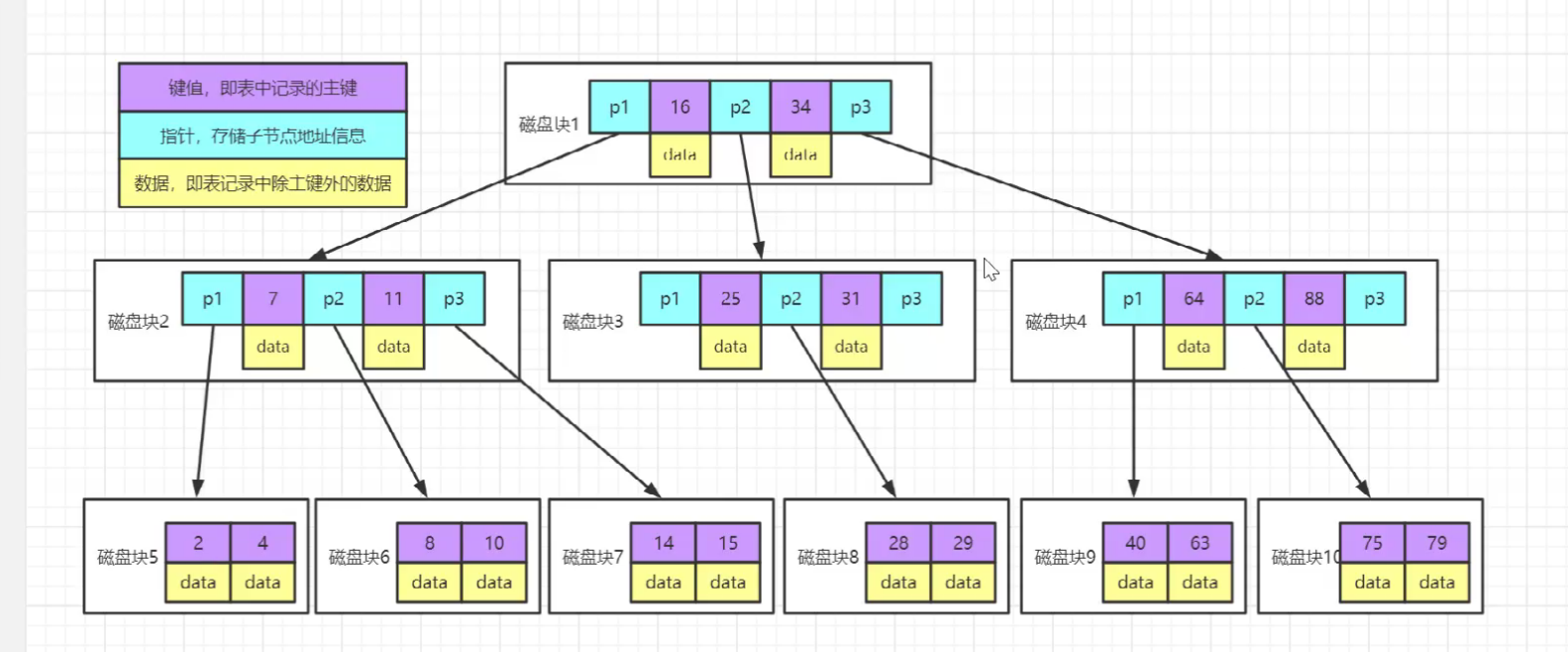
B+树

一般情况下,3-4层的B+树足以支撑千万级别的数据量存储
层数跟数量和key值占用的存储空间有关,key越小越好
聚簇索引
以主键建立的一课b+树,根节点指向实际存储数据的磁盘块的指针。而非聚簇索引,也就是我们平时自己建立的索引,根节点存放的是主键id,可能需要回表进行查询。
索引设计原则

1.索引字段小,b+树中每一个节点就能存放更多的指针,使得层数减少。
2.唯一值少,也就是重复的多,则查索引后,如果没有建组合索引的话,会导致大量的回表,反而比全表查询访问的数据块更多,速度更慢
3.频繁更新,会导致频繁更新b+数。
4.null的行不会参与b+树的建立。
5.索引太多,维护成本高。
回表,索引覆盖
什么是回表?
表:ia,name,age,genaer
id主键,name是普通索引
select from table where name=’zhangsan’;
查找过程:先根据name的值去name的B+树中进行检索,获取到了id的值,然后根据id去id的B+树中查找,找到整行的记录,这个过程叫做回表
回表:效率低,尽量避免回表
什么是索引覆盖?
表:id,name,age,gender
id主键,name是普通索引
select id,name from table where name=’zhangsan’;
查找过程:直接根据name的值去name的B+树中查找对应的值,然后发现name索引的叶子节点中包含了要查询的所有字段,此时不需要回表,直接返回结果即可,这叫做索引覆盖
索引覆盖:效率高,推荐使用
组合索引
给id创建索引:create index t1_id on t1(id);
创建组合索引的语法:create index 索引名 on 表名(字段名1,字段名2)
最左匹配

如果name,age,gender是组合索引
查name,gender则只会用name
explain 语句。mysql会显示一些来自于优化器的关于sql执行计划的信息。
如果组合索引覆盖了所有列,则一直会使用组合索引
key_len表示key占用的存储空间int是 4+1, 1是表示非空
索引失效
核心思想:b+树的结构导致需要满足最左匹配才可以走索引。以及回表的情况,如果优化器觉得全表搜索更快,那么不会走索引。
1.违反最左匹配。不是有序的。
2.多个范围查询。违反b+树,第一个字段有序,第二个不是有序的。
3.使用不等于(!=或者<>)。如果没有覆盖索引(要查询的列都在索引上,不用回表,这才是根本原因),那么就会变成全表查询。
4.通配符开头%,同样需要考虑是否覆盖索引。
5.字符串不加引号。
6.如果条件中有or,类似每次考虑一个条件,进行多个查询,如果某个条件没有索引,那么即没有走索引。要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引。
7.order by 用非索引字段,或者违反了最左匹配原则
死锁
show engine innodb status\G;
找lasted detected deadlock
原理-事务
把多条语句作为一个整体进行操作的功能,被称为数据库事务。
对于单条SQL语句,数据库系统自动将其作为一个事务执行,这种事务被称为隐式事务。
要手动把多条SQL语句作为一个事务执行,使用BEGIN开启一个事务,使用COMMIT提交一个事务,这种事务被称为显式事务
事务的四个特点
ACID
原子性(atomicity,或称不可分割性)
一个事务的多个语句 要么全部成功要么全部失败
思路:执行相反操作/记录历史状态
原理: mysql则是用记录历史状态, undolog回滚日志
隔离性(isolation,又称独立性)
事务之间互不影响,假如同时来了a事务和b事务,不能让互相影响。有四个级别
原理:单纯的锁效率低->mvcc
持久性(durability)
从内存持久化到硬盘,io问题
原理:redolog
数据修改时涉及到随机读写,写日志时则是顺序读写(append)
从内存到磁盘随机读写慢,那么想个磁盘缓存顺序写,那就是redolog。断电恢复后,根据redolog恢复到磁盘。假如断电时,也没写进redolog,那么就是真正意义的丢失,没有人能做到100,云存储也是几个9。
思想:预写日志,wal write ahead log。
最终要求是,一致性(consistency),前三个保证了数据的一致性。即正确符合预期的。事务的产生,其实是为了当应用程序访问数据库的时候,事务能够简化我们的编程模型,不需要我们去考虑各种各样的潜在错误和并发问题。
(延伸,一致性在不同场景下的含义)
CAP理论的最终一致性,在分布式系统中,可以理解为多个节点中数据的值在一定时间之后是一样的。
一致性哈希。来避免分布式系统在扩容或者缩容时,发生过多的数据迁移。
InnoDB引擎 四种事务隔离级别

Read Uncommitted(读取未提交内容) >> 在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read)。
Read Committed(读取提交内容) >> 这是大多数数据库系统的默认隔离级别(但不是 MySQL 默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。会出现不可重复读(Nonrepeatable Read),事务中的多个相同 select 可能返回不同结果,因为其他事务可能会有新的 commit。
Repeatable Read(可重读) >> 这是 MySQL 的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。InnoDB 和 Falcon 存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control 间隙锁)机制解决了所有不可重复读和部分幻读问题。(多版本只是解决不可重复读问题,而加上间隙锁才解决了部分幻读问题,但是解决不了所有幻读。)
不过理论上,这会导致另一个棘手的问题:幻读(PhantomRead)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行,数据总量不一致。
Serializable(可串行化) >> 这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而彻底解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
MVCC多版本并发控制是什么
多版本并发控制技术的英文全称是 Multiversion Concurrency Control,简称 MVCC。
多版本并发控制(MVCC) 是通过保存数据在某个时间点的快照来实现并发控制的。也就是说,不管事务执行多长时间,事务内部看到的数据是不受其它事务影响的,根据事务开始的时间不同,每个事务对同一张表,同一时刻看到的数据可能是不一样的。
简单来说,多版本并发控制 的思想就是保存数据的历史版本,通过对数据行的多个版本管理来实现数据库的并发控制。这样我们就可以通过比较版本号决定数据是否显示出来,读取数据的时候不需要加锁也可以保证事务的隔离效果。
可以认为 多版本并发控制(MVCC) 是行级锁的一个变种,但是它在很多情况下避免了加锁操作,因此开销更低。虽然实现机制有所不同,但大都实现了非阻塞的读操作,写操作也只锁定必要的行。
MySQL的大多数事务型存储引擎实现的都不是简单的行级锁。基于提升并发性能的考虑,它们一般都同时实现了多版本并发控制(MVCC)。不仅是MySQL,包括Oracle、PostgreSQL等其他数据库系统也都实现了MVCC,但各自的实现机制不尽相同,因为MVCC没有一个统一的实现标准,典型的有乐观(optimistic)并发控制和悲观(pessimistic)并发控制。
MVCC解决了哪些问题?
- 读写之间阻塞的问题
通过 MVCC 可以让读写互相不阻塞,即读不阻塞写,写不阻塞读,这样就可以提升事务并发处理能力。
最早的数据库系统,只有读读之间可以并发,读写,写读,写写都要阻塞。引入多版本之后,只有写写之间相互阻塞,其他三种操作都可以并行
提高并发的演进思路:
- 普通锁,只能串行执行;
- 读写锁,可以实现读读并发;
- 数据多版本并发控制,可以实现读写并发。
- 降低了死锁的概率
因为 InnoDB 的 MVCC 采用了乐观锁的方式,读取数据时并不需要加锁,对于写操作,也只锁定必要的行。
- 解决一致性读的问题
一致性读也被称为快照读,当我们查询数据库在某个时间点的快照时,只能看到这个时间点之前事务提交更新的结果,而不能看到这个时间点之后事务提交的更新结果。
快照读与当前读
快照读(SnapShot Read) 是一种一致性不加锁的读,是InnoDB并发如此之高的核心原因之一。
这里的一致性是指,事务读取到的数据,要么是事务开始前就已经存在的数据,要么是事务自身插入或者修改过的数据。
不加锁的简单的 SELECT 都属于快照读,例如:
SELECT * FROM t WHERE id=1与 快照读 相对应的则是 当前读,当前读就是读取最新数据,而不是历史版本的数据。加锁的 SELECT 就属于当前读,例如:
SELECT * FROM t WHERE id=1 LOCK IN SHARE MODE;
SELECT * FROM t WHERE id=1 FOR UPDATE;InnoDB 是如何存储记录的多个版本的
事务版本号
每开启一个事务,我们都会从数据库中获得一个事务 ID(也就是事务版本号),这个事务 ID 是自增长的,通过 ID 大小,我们就可以判断事务的时间顺序。
行记录的隐藏列
InnoDB 的叶子段存储了数据页,数据页中保存了行记录,而在行记录中有一些重要的隐藏字段:
DB_ROW_ID:6-byte,隐藏的行 ID,用来生成默认聚簇索引。如果我们创建数据表的时候没有指定聚簇索引,这时 InnoDB 就会用这个隐藏 ID 来创建聚集索引。采用聚簇索引的方式可以提升数据的查找效率。这个DB_ROW_ID跟MVCC关系不大。DB_TRX_ID:6-byte,操作这个数据的事务 ID,也就是最后一个对该数据进行插入或更新的事务 ID。DB_ROLL_PTR:7-byte,回滚指针,也就是指向这个记录的 Undo Log 信息。

Undo Log
InnoDB 将行记录快照保存在了 Undo Log 里,我们可以在回滚段中找到它们,如下图所示:
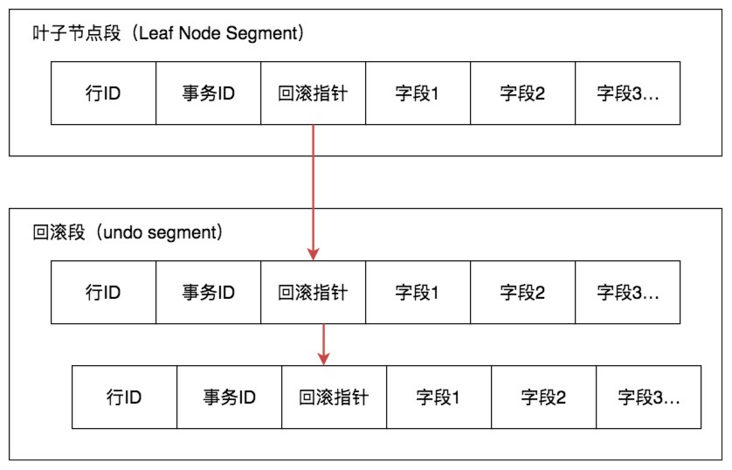
从图中能看到回滚指针将数据行的所有快照记录都通过链表的结构串联了起来,每个快照的记录都保存了当时的 db_trx_id,也是那个时间点操作这个数据的事务 ID。这样如果我们想要找历史快照,就可以通过遍历回滚指针的方式进行查找。
在 可重复读(REPEATABLE READ) 隔离级别下, InnoDB 的 MVCC 是如何工作的
查询(SELECT)
InnoDB 会根据以下两个条件检查每行记录:
-
InnoDB只查找版本早于当前事务版本的数据行(也就是,行的系统版本号小于或等于事务的系统版本号),这样可以确保事务读取的行,要么是在事务开始前已经存在的,要么是事务自身插入或者修改过的。
注解:InnoDB只查找版本早于当前事务版本的数据行。这个结论是错误的,应该是已提交修改的版本中的事务id最大的版本。只是这样比较的话大于当前事务id,但是已提交的一些事务修改形成的快照也看不到了,因为不是在事务一开始就产生一致性读的问题的,而是在事务开始后第一次读才可能产生一致性问题。而且一些事务小于当前事务id,但是还未提交,读取这样的事务提交形成的版本,就会读到脏数据。其实应该查找事务第一次进行查询(在可重复读级别)或者每次查询(在读已提交级别)前,也就是创建readview时已提交修改的版本中的事务id最大的版本。
-
行的删除版本要么未定义,要么大于当前事务版本号。这可以确保事务读取到的行,在事务开始之前未被删除。
只有符合上述两个条件的记录,才能返回作为查询结果。
插入(INSERT)
InnoDB为新插入的每一行保存当前系统版本号作为行版本号。
删除(DELETE)
InnoDB为删除的每一行保存当前系统版本号作为行删除标识。
删除在内部被视为更新,行中的一个特殊位会被设置为已删除。
每一条记录除了三个隐藏字段外,还包含额外字段,不同行格式的额外字段有一些差异,但是删除标志都是在额外字段的记录头信息中,这里以 COMPACT行格式 为例:
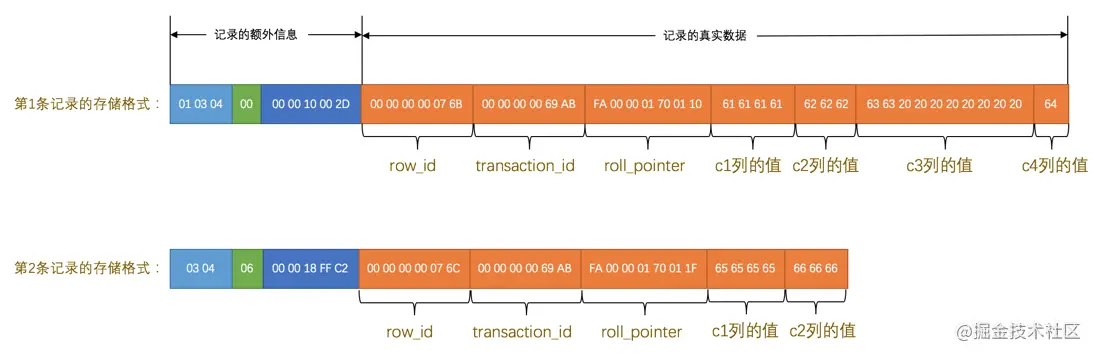
图中记录额外信息的三个字段分别为:变长字段长度列表、NULL值列表、记录头信息。
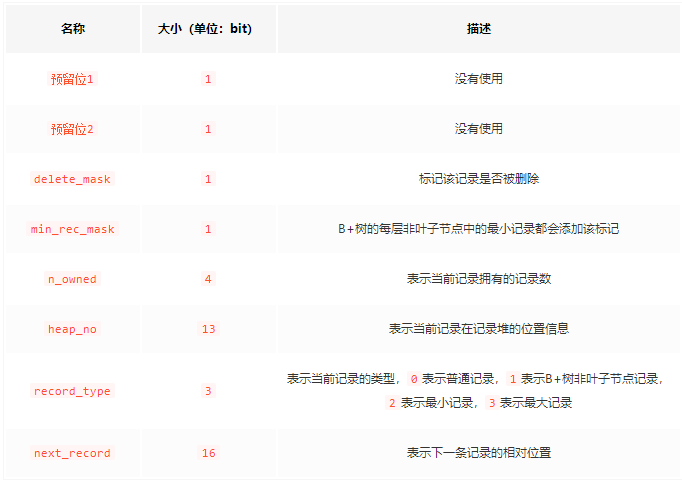
记录头信息 是由固定的5个字节组成。5个字节也就是40个二进制位,不同的位代表不同的意思,删除标志位就在 记录头信息 中,如图:
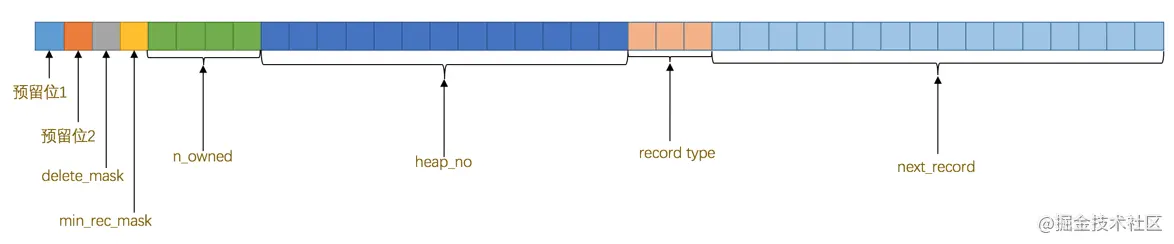
这些二进制位代表的详细信息如下表:
更新(UPDATE)
InnoDB为插入一行新记录,保存当前系统版本号作为行版本号,同时保存当前系统版本号到原来的行作为行删除标识。
Read View 结构(重点)
其实Read View(读视图),跟快照、snapshot是一个概念。
Read View主要是用来做可见性判断的, 里面保存了“对本事务不可见的其他活跃事务”。

① low_limit_id:\目前出现过的最大的事务ID+1,即下一个将被分配的事务ID。源码 350行:

max_trx_id的定义如下,源码 628行,翻译过来就是“还未分配的最小事务ID”,也就是下一个将被分配的事务ID。(low_limit_id 并不是活跃事务列表中最大的事务ID)

② up_limit_id活跃事务列表trx_ids中最小的事务ID,如果trx_ids为空,则up_limit_id 为 low_limit_id。源码 358行:
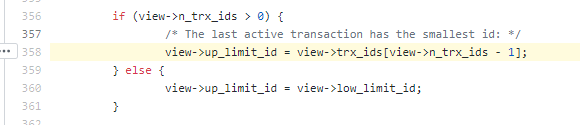
因为trx_ids中的活跃事务号是逆序的,所以最后一个为最小活跃事务ID。(up_limit_id 并不是已提交的最大事务ID+1,后面的 例子2 会证明这是错误的)
③ trx_ids:Read View创建时其他未提交的活跃事务ID列表。意思就是创建Read View时,将当前未提交事务ID记录下来,后续即使它们修改了记录行的值,对于当前事务也是不可见的。
注意:Read View中trx_ids的活跃事务,不包括当前事务自己和已提交的事务(正在内存中),源码 295行:
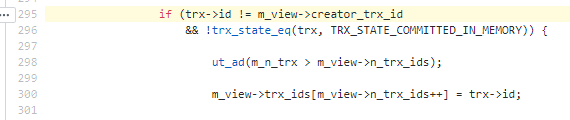
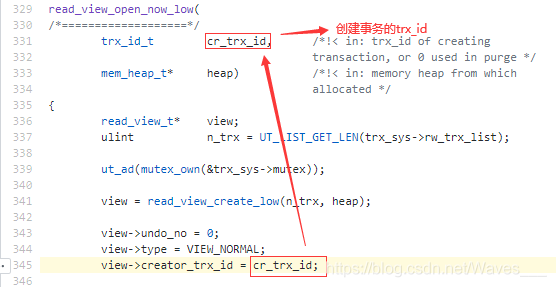
④ creator_trx_id:当前创建事务的ID,是一个递增的编号,源码 345行 。(这个编号并不是DB_ROW_ID)
InnoDB 的行锁怎么实现
InnoDB 行锁是通过给索引上的索引项加锁来实现的,这一点 MySQL 与Oracle 不同,后者是通过在数据块中对相应数据行加锁来实现的。InnoDB 这种行锁实现特点意味着:只有通过索引条件检索数据,InnoDB 才使用行级锁,否则,InnoDB 将使用表锁!
总结
多版本并发控制(MVCC) 在一定程度上实现了读写并发,它只在 可重复读(REPEATABLE READ) 和 提交读(READ COMMITTED) 两个隔离级别下工作。其他两个隔离级别都和 MVCC 不兼容,因为 未提交读(READ UNCOMMITTED),总是读取最新的数据行,而不是符合当前事务版本的数据行。而 可串行化(SERIALIZABLE) 则会对所有读取的行都加锁。
行锁,并发,事务回滚等多种特性都和MVCC相关。
两阶段提交-分布式一致性
主从的时候为了保持两台机器是 一致性
同步binlog。此时应该先写binlog还是先写redolog?
假设,binlog已经是一致的。断电恢复根据redolog
假如a先写redolog后断电了,a能恢复, b能吗?如果能,那一定是a重新追加了binlog,并且b重新读了a的binlog。但是实际上,a宕机后,b承载业务,已经修改了很多binlog,无法重新读a的binlog,而是应该a服从于b的binlog。所以不能。 b不应该去同步宕机的。
假如先写binlog,断电后,可能b更新了,但是a因为redolog没有写,无法恢复,于是丢失了。
总之都可能会出现丢失的情况,因此,出现了两阶段提交,a多进行一次判断。
从上面的分析,a写完redolog宕机,恢复应该遵从b的结果来看。既然a多了一条,那么我们应该丢弃这条。只有当确定ab的binlog都已经同步完成后,即redo:commit时,才保留a的这条数据。
具体来说就是,a宕机,上线后,读取b的binlog,如果b的binlog有a当时新增的那条,则a也恢复那条。如果b中没有,那就丢弃。
所以,两阶段,是为了保证a的这个提交真的成功同步了,只有一次无法确定是否真的同步成功。分成两阶段是为了打个标签,以便宕机恢复时确定比对哪些。不打标签则是默认成功。会导致问题。
根本原因:binlog不能插入,只能追加。
redolog:prepare
binlog
redolog:commit
原理-集群
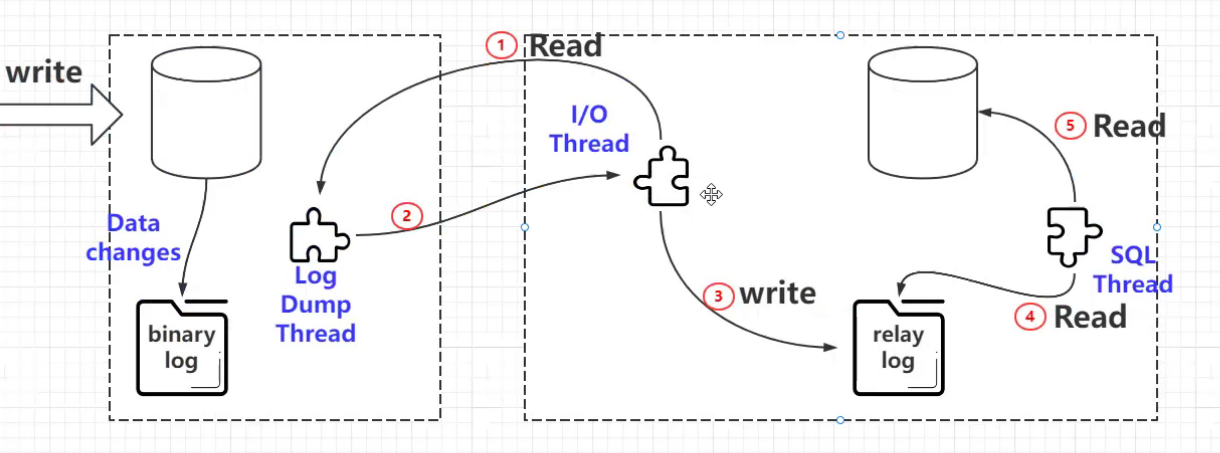
mysql 的复制原理以及流程
Mysql 内建的复制功能是构建大型,高性能应用程序的基础。将 Mysql 的数据分布到多个系统上去,这种分布的机制,是通过将 Mysql 的某一台主机的数据复制到其它主机(slaves)上,并重新执行一遍来实现的。
复制过程中一个服务器充当主服务器,而一个或多个其它服务器充当从服务器。主服务器将更新写入二进制日志文件,并维护文件的一个索引以跟踪日志循环。这些日志可以记录发送到从服务器的更新。 当一个从服务器连接主服务器时,它通知主服务器在日志中读取的最后一次成功更新的位置。从服务器接收从那时起发生的任何更新,然后封锁并等待主服务器通知新的更新。
过程如下
- 主服务器把更新记录到二进制日志文件中。mysqladmin -uroot -pwater123 flush-logs 刷新日志
- 从服务器把主服务器的二进制日志拷贝到自己的中继日志(replay log)中。
- 从服务器重做中继日志中的语句,把更新应用到自己的数据库上。
/var/lib/mysql目录下mysql-bin.index是日志的元文件,记录了多个如mysql-bin.000001这样的日志
mysqldump可以进行全量备份,而用二进制日志则可以实现增量备份
mysql 支持的复制类型?
基于语句的复制: 在主服务器上执行的 SQL 语句,在从服务器上执行同样的语句。MySQL 默认采用基于语句的复制,效率比较高。 一旦发现没法精确复制时,会自动选着基于行的复制。
基于行的复制:把改变的内容复制过去,而不是把命令在从服务器上执行一遍. 从 mysql5.0 开始支持
混合类型的复制: 默认采用基于语句的复制,一旦发现基于语句的无法精确的复制时,就会采用基于行的复制。
Redis
使用
常用命令
redis-cli #启动客户端
SET GET #String
HMSET HGET #hash
LPUSH RPOP #list,这个有很多不是按照List首字母开头的命令
SADD #set
ZADD #sorted set一个string类型的值能存储最大容量是多少?
一个key或是value大小最大是512M
最多能存多少key?
2^32 keys 一个key的value里还可以有2^32个
key 的过期时间和永久有效分别怎么设置?
EXPIRE 和 PERSIST 命令
如何保证 redis 中的数据都是热点数据?
MySQL 里有 2000w 数据,redis 中只存 20w 的数据,限制内存大小。
redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。
支持的 Java 客户端都有哪些?官方推荐用哪个?
Jedis(springboot 1.5.x)、lettuce(Springboot 2.x) ,Redisson等等,官方推荐使用 Redisson。
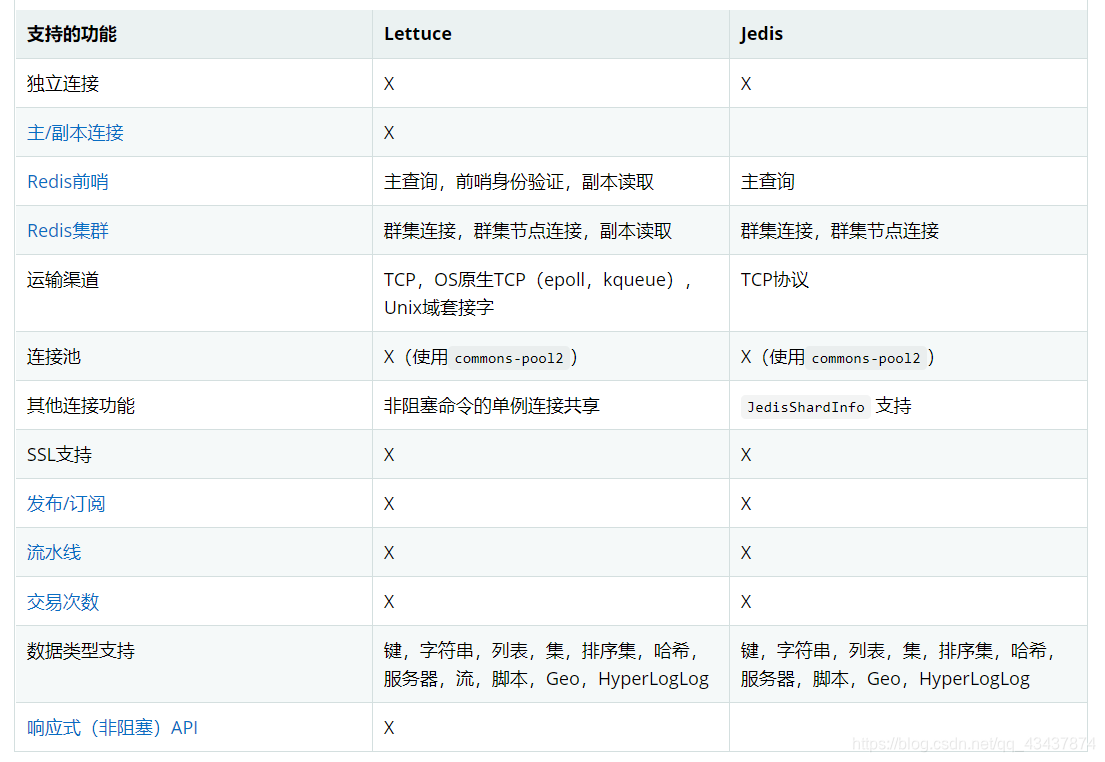
Lettuce 和 jedis 的都是连接 Redis Server的客户端,Jedis 在实现上是直连 redis server,多线程环境下非线程安全,因为是只有一个连接,共享套接字不做处理显然会出问题,除非使用连接池,为每个线程安排一个连接。
Lettuce 是 一种可伸缩,线程安全,非阻塞的Redis客户端,多个线程可以共享一个RedisConnection,它利用Netty NIO 框架来高效地管理多个连接。
Redisson 是一个高级的分布式协调 Redis 客服端,能帮助用户在分布式环境中轻松实现一些 Java 的对象 (Bloom filter, BitSet, Set, SetMultimap, ScoredSortedSet, SortedSet, Map, ConcurrentMap, List,ListMultimap, Queue,BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, ReadWriteLock,AtomicLong, CountDownLatch, Publish / Subscribe, HyperLogLog)。
提供很多分布式相关操作服务,例如,分布式锁,分布式集合,可通过Redis支持延迟队列等。
Jedis 与 Redisson 对比
Jedis 是 Redis 的 Java 实现的客户端,其 API 提供了比较全面的 Redis 命令的支持。
Redisson 实现了分布式和可扩展的 Java 数据结构,和 Jedis 相比,功能较为简单,不支持字符串操作,
不支持排序、事务、管道、分区等 Redis 特性。Redisson 的宗旨是促进使用者对 Redis 的关注分离,
从而让使用者能够将精力更集中地放在处理业务逻辑上。
相当于一个是底层api,一个是做了很多高级封装。
基本特点
https://cloud.tencent.com/developer/article/1796691 Redis 日志篇
https://www.jianshu.com/p/e71c5a3a7162 redis主从配置
https://www.cnblogs.com/kevingrace/p/9004460.html redis哨兵模式
什么是 Redis?
Redis 的全称是:Remote Dictionary Server,本质上是一个 Key-Value 类型的内存数据库。
简述它的优缺点?
高性能:因为是纯内存操作,单线程多路复用,避免锁竞争,每秒可以处理超过 10 万次读写操作,是已知性能最快的Key-Value DB。
多种数据结构,此外单个 value 的最大限制是 1GB,不像 memcached 只能保存 1MB 的数据,因此 Redis 可以用来实现很多有用的功能。
比方说
String 做缓存
Hash 存对象
List 来做 FIFO 双向链表,实现一个轻量级的高性能消息队列服务,用他的 Set 可以做高性能的 tag 系统等等。
sorted set 排行榜
另外 Redis 也可以对存入的 Key-Value 设置 expire 时间,因此也可以被当作一 个功能加强版的memcached 来用。
定期通过异步操作把数据库数据 flush 到硬盘上进行保存
缺点是数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此 Redis 适合的场景主要局限在较小数据量的高性能操作和运算上。
支持的数据类型?
String、List、Set、Sorted Set、hash
(延伸,hash)
特别适合存对象
hash multiple set get
HMSET KEY_NAME FIELD1 VALUE1 ...FIELDN VALUEN
HMGET KEY_NAME FIELD1...FIELDN
HGET key field
HSET key field原理-单线程
多路复用
Redis基于Reactor模式(应答者模式,是基于事件驱动的设计模式,核心思想是减少等待)开发了自己的I/O事件处理器,也就是文件事件处理器,Redis在I/O事件处理上,采用了I/O多路复用技术,同时监听多个套接字,并为套接字关联不同的事件处理函数,通过一个线程实现了多客户端并发处理。
但是,实际上Redis也并不是单线程的,比如生成RDB文件,就会fork一个子进程来实现。实际上redis核心有两个线程,分别是多路复用和分配器。我们说的单线程是io多路复用程序,这个线程用了epoll多路复用函数,监听多个fd。当有套接字发生read或write事件时,epoll函数会返回这些套接字,然后我们放入一个队列中。分派器就按照顺序一个一个的处理,根据事件类型调用不同的事件处理器函数来处理。
http://redisbook.com/preview/event/file_event.html

经常听到的AE_READABLE事件,其实是redis对于epoll的事件的封装。epollin,epollout。
I/O 多路复用程序 可以监听多个套接字的 ae.h/AE_READABLE 事件和 ae.h/AE_WRITABLE 事件, 这两类事件和套接字操作之间的对应关系如下:
- 当套接字变得可读时(客户端对套接字执行
write操作,或者执行close操作), 或者有新的可应答(acceptable)套接字出现时(客户端对服务器的监听套接字执行connect操作), 套接字产生AE_READABLE事件。 -
当套接字变得可写时(客户端对套接字执行
read操作), 套接字产生AE_WRITABLE事件。如果一个套接字又可读又可写的话, 那么服务器将先读套接字, 后写套接字。
(延伸)常用的io复用函数。
select=通常作备选安装在所有平台上
evport用于Solaris 10系统
epoll用于linux
kqueue用于os x,freebsd
epoll原理
1.epoll_create的时候在内核cache里会额外建了个红黑树用于存储以后epoll_ctl传来的socket支持快速查找插入删除,还会再建立一个list链表,用于存储准备就绪的事件。
2.epoll_ctl用于把socket放到epoll文件系统里file对象对应的红黑树上,还会给内核中断处理程序注册一个回调函数,告诉内核,如果这个fd的中断到了,就把它放到准备就绪list链表里。所以,当一个socket上有数据到了,内核在把网卡上的数据copy到内核中后就来把socket插入到准备就绪链表里了。
3.epoll_wait查看在create阶段创建的list列表是否有数据,有数据就返回,没有就等待,所以是O(1)
Lazy Free机制
Redis在4.0版本引入了Lazy Free
将大键的删除操作异步化,采用非阻塞删除(对应命令UNLINK),大键的空间回收交由单独线程实现,主线程只做关系解除,可以快速返回,继续处理其他事件,避免服务器长时间阻塞。
io 多线程
Redis的性能瓶颈并不在CPU上,而是在内存和网络上。所以6.0发布的多线程并未将事件处理改成多线程,而是在I/O上。用来处理网络数据的读写和协议解析,执行命令仍然是单线程顺序执行。不会存在线程并发的安全问题
修改redis.conf文件的
io-threads-do-reads yes #启用多线程
io-threads 6 #线程数原理-缓存过期处理
- 惰性(被动)删除:当读/写一个已经过期的key时,会触发惰性删除策略,直接删除掉这个过期key
- 定期(主动)删除:由于惰性删除策略无法保证冷数据被及时删掉,所以Redis会定期主动淘汰一批已过期的key
- 当前已用内存超过maxmemory限定时,触发主动清理策略
定时删除:
会调用activeExpireCycle函数,针对每个db在限制的时间REDIS_EXPIRELOOKUPS_TIME_LIMIT(timelimit = 1000000*ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC/server.hz/100, ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC 是个宏定义25,hz默认10,最终算出来是250ms)内迟可能多的删除过期key。
- 随机测试100个设置了过期时间的key
- 删除所有发现的已过期的key
- 若删除的key超过25个则重复步骤1
当REDIS运行在主从模式时,只有主结点才会执行被动和主动删除策略,然后把删除操作”del key”同步到从结点。
原理-淘汰策略?
redis根本就不会准确的将整个数据库中最久未被使用的键删除,而是每次从数据库中随机取5个键并删除这5个键里最久未被使用的键。上面提到的所有的随机的操作实际上都是这样的,这个5可以用过redis的配置文件中的maxmemeory-samples参数配置。
1.no eviction(不逐出):当内存限制达到,返回错误,并且客户端尝试执行会让更多内存被使用的命令。
2.allkeys-lru: 尝试回收最少使用的键(LRU)。
3.volatile-lru: 尝试回收最少使用的键(LRU),但仅限于在过期集合的键,
4.allkeys-random: 回收随机的键使得新添加的数据有空间存放。
5.volatile-random: 回收随机的键使得新添加的数据有空间存放,但仅限于在过期集合的键。
6.volatile-ttl: 回收在过期集合的键,并且优先回收存活时间(TTL)较短的键
(延伸,四种页面置换算法)
OPT最佳算法,淘汰最长时间不被访问(极限情况下永久不再用)的页面,无法实现,但可以用来评价其他算法,
FIFO先进先出,只有他可能出现Belady异常,增加物理块,缺页次数反而增加
LRU最近最久未使用,开销较大。理论上可以证明堆栈类算法不可能出现Belady异常。
CLOCK时钟,用较小的开销逼近LRU。简单的CLOCK算法,NRU。每个页面串起来一个循环队列,增加一个访问位,访问时置为1.并且有个替换指针,挨个遍历,碰到0则替换,碰到1则置为0
改进型CLOCK置换算法。如果一个页面修改过,则替换前要先写回磁盘,显然修改过的页面替换的代价更大。因此增加一个修改位。算法性能下降,但是可以减少io次数。
首先是扫描寻找既未访问也未修改过的页面,注意最多扫描一整轮。
如果没找到,则找未被访问,但已经被修改的的。并且扫过的访问位都置为0
如果一轮过后仍未找到,则所有帧的访问位置为0,重复上述步骤
原理-持久化
结论-如何选择RDB和AOF
- 如果是数据不那么敏感,且可以从其他地方重新生成补回的,那么可以关闭持久化
- 如果是数据比较重要,不想再从其他地方获取,且可以承受数分钟的数据丢失,比如缓存等,那么可以只使用RDB
- 如果是用做内存数据库,要使用Redis的持久化,建议是RDB和AOF都开启,或者定期执行
bgsave(fork一个子进程,不阻塞,子进程会把数据集先写入临时文件,写入成功之后,再替换之前的RDB文件,用二进制压缩存储,这样可以保证RDB文件始终存储的是完整的持久化内容)主动做快照备份,RDB方式更适合做数据的备份,AOF可以保证数据的不丢失
RDB
RDB持久化会生成RDB文件,该文件是一个压缩过的二进制文件
触发快照的时机
- 执行
save和bgsave命令 - 配置文件设置
save <seconds> <changes>规则,自动间隔性执行bgsave命令 - 主从复制时,从库全量复制同步主库数据,主库会执行
bgsave - 执行
flushall命令清空服务器数据 - 执行
shutdown命令关闭Redis时,会执行save命令
AOF(Append Only File)
AOF需要记录Redis的每个写命令,步骤为:命令追加(append)、文件写入(write)和文件同步(sync)
开启AOF持久化功能后,服务器每执行一个写命令,都会把该命令以协议格式先追加到aof_buf缓存区的末尾,而不是直接写入文件,避免每次有命令都直接写入硬盘,减少硬盘IO次数.
对于何时把aof_buf缓冲区的内容写入保存在AOF文件中,Redis提供了多种策略
appendfsync always:将aof_buf缓冲区的所有内容写入并同步到AOF文件,每个写命令同步写入磁盘appendfsync everysec:将aof_buf缓存区的内容写入AOF文件,每秒同步一次,该操作由一个线程专门负责appendfsync no:将aof_buf缓存区的内容写入AOF文件,什么时候同步由操作系统来决定
appendfsync选项的默认配置为everysec,即每秒执行一次同步
AOF 重写并不需要对原有的 AOF 文件进行任何写入和读取, 它针对的是数据库中键的当前值。AOF重写的目的就是减小AOF文件的体积。
数据恢复
Redis4.0开始支持RDB和AOF的混合持久化(可以通过配置项 aof-use-rdb-preamble 开启)
- 如果是redis进程挂掉,那么重启redis进程即可,直接基于AOF日志文件恢复数据
- 如果是redis进程所在机器挂掉,那么重启机器后,尝试重启redis进程,尝试直接基于AOF日志文件进行数据恢复,如果AOF文件破损,那么用
redis-check-aof fix命令修复 - 如果没有AOF文件,会去加载RDB文件
- 如果redis当前最新的AOF和RDB文件出现了丢失/损坏,那么可以尝试基于该机器上当前的某个最新的RDB数据副本进行数据恢复
原理-集群
有哪些方案?
1.codis。twitter的Twemproxy。Twemproxy 本身是一个静态的分布式方案,进行扩容、缩容的时候对我们devops的要求很高,而且很难得做到平滑的扩容、缩容。而且没有用于集群管理的 Dashboard,这样十分不便。为了解决这些痛点,豌豆荚开源了它们的 Codis。已停止维护。
2.redis cluster3.0 自带的集群。支持在节点数量改变情况下,旧节点数据可恢复到新 hash 节点。
特点在于他的分布式算法不是一致性 hash,而是 hash 槽的概念,以及自身支持节点设置从节点。
3.在业务代码层实现,起几个毫无关联的 redis 实例,在代码层,对 key 进行 hash 计算,然后去对应
的 redis 实例操作数据。这种方式对 hash 层代码要求比较高,考虑部分包括,节点失效后的替代算法
方案,数据震荡后的自动脚本恢复,实例的监控,等等。
(延伸,一致性哈希算法)
传统的哈希取模算法,对于分布式缓存这种的系统而言,映射规则失效就意味着之前缓存的失效,若同一时刻出现大量的缓存失效,则可能会出现 “缓存雪崩”,这将会造成灾难性的后果。
锁或者队列,二级缓冲备份,失效时间均匀(这里显然不行)
在移除或者添加一个服务器时,能够尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系。
哈希环,对象和服务器ip计算hash放在环上,对象顺时针寻找下一个最近的服务器。
虚拟节点,增加一层中间层,把虚拟节点放在环上,而虚拟节点和实际服务器的关系可以再指定
延伸,哈希槽的概念?
Redis 集群没有使用一致性 hash,而是用哈希槽的概念,不过其实和带虚拟节点的一致性哈希很像,虚拟节点相当于哈希槽了。只不过数据切片的方式不太一样,一致性哈希是key直接模2^32,哈希槽则是先计算key,再计算key的crc16,然后再模2^14=16384 ,集群的每个节点负责一部分 hash 槽。两者分散的粒度不同,哈希槽的2^14直接就是结果,一致性哈希还需再计算虚拟节点。
一致性哈希的某个节点宕机或者掉线后,当该机器上原本缓存的数据被请求时,会从数据源重新获取数据,并将数据添加到失效机器后面的机器,这个过程被称为 "缓存抖动" ,而使用哈希槽的节点宕机,会导致一定范围内的槽不可用,只能通过主从复制加哨兵模式保证高可用。
什么情况下会导致整个集群不可用?
有 A,B,C 三个节点的集群,在没有复制模型的情况下,如果节点 B 失败了,那么整个集群就会以为缺
少 5501-11000 这个范围的槽而不可用。
主从复制模型是怎样的?
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,
每个节点都会有 N-1 个复制品.
key过期时保证主从的一致
为了获得正确的行为而不至于导致一致性问题,当一个key过期时DEL操作将被记录在AOF文件并传递到所有相关的slave。也即过期删除操作统一在master实例中进行并向下传递,而不是各salve各自掌控。这样一来便不会出现数据不一致的情形。当slave连接到master后并不能立即清理已过期的key(需要等待由master传递过来的DEL操作),slave仍需对数据集中的过期状态进行管理维护以便于在slave被提升为master会能像master一样独立的进行过期处理。
集群会有写操作丢失吗?为什么?
Redis 并不能保证数据的强一致性,这意味这在实际中集群在特定的条件下可能会丢失写操作。
集群之间是如何复制的?
异步复制
基本通信原理:gossip协议
Goosip协议也可以叫流言协议Gossip 过程是由种子节点发起,当一个种子节点有状态需要更新到网络中的其他节点时,它会随机的选择周围几个节点散播消息,收到消息的节点也会重复该过程,直至最终网络中所有的节点都收到了消息。这个过程可能需要一定的时间,由于不能保证某个时刻所有节点都收到消息,但是理论上最终所有节点都会收到消息,因此它是一个最终一致性协议。
管道,事务,lua脚本
管道
将多条命令打包一次性发送给服务端。
特点:快,不具备原子性,指令执行失败, Pipelining仍会继续执行
减少了客户端与服务端之间的网络调用次数,当客户端/服务端需要从网络中读写数据时,都会产生一次系统调用,程序由用户态切换到内核态,再从内核态切换回用户态。
事务
适用于,不需要事务中间命令的执行结果来编排后面的命令
特点:原子性,但不具备失败回滚。可以watch一个值,类似cas。
怎么理解 Redis 事务?
事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行,事务在执行的过程中,不会
被其他客户端发送来的命令请求所打断。
事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
如果客户端处于非事务状态下,那么所有发送给服务端的命令都会立即被服务器执行,而如果客户端处于事务状态下,那么所有命令都还不会立即执行,而是被发送到一个事务队列中,返回 QUEUED,表示入队成功。
Redis 事务相关的命令有哪几个?
MULTI开启事务、EXEC提交、DISCARD回滚、WATCH
WATCH
Watch 命令用于监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断
WATCH 命令只能在客户端进入事务状态之前执行, 在事务状态下发送 WATCH 命令会引发错误
redis 中保存了一个 watched_keys 字典,字典的键是这个数据库被监视的键,而字典的值则是一个链表,链表中保存了所有监视这个键的客户端
每当一个客户端执行 WATCH 命令,对应的 key 指向的链表中就会增加该客户端的节点

图意味着,key1 正在被 client1 和 client2 两个客户端监视着,key2 被 client3 监视着,key3 被 client4 监视着
一旦对数据库键空间进行的修改成功执行,multi.c 的 touchWatchedKey 函数都会被调用,他的工作就是遍历上述字典中该 key 所对应的整个链表的所有节点,打开每一个 WATCH 该 key 的 client 的 REDIS_DIRTY_CAS 选项,
当客户端发送 EXEC 命令触发事务执行时,服务器会对客户端状态进行检查,如果客户端的 REDIS_DIRTY_CAS 选项已经被打开,那么说明被客户端监视的键至少有一个已经被修改,事务安全性已经被破坏,则服务端直接向客户端返回空回复,表示事务执行失败
当一个客户端结束它的事务时,无论事务是成功执行,还是失败, watched_keys 字典中和这个客户端相关的资料都会被清除。
lua脚本
可以在脚本中获取中间命令的返回结果,然后根据结果值做相应的处理。
特点:原子性,可获取中间结果,处理复杂业务
调优
Redis 如何做内存优化?
尽可能使用散列表(hashes),尽可能的将数据模型抽象到一个散列表里面。
比如你的 web 系统中有一个用户对象,不要为这个用户的名称,姓氏,邮箱,密码设置单独的 key,而
是应该把这个用户的所有信息存储到一张散列表里面。
应用-缓存
最主要的作用,缓存mysql中的部分热点数据,存储对象适合用hash,这样可以修改部分内容。
缓存有两个场景问题,缓存穿透和缓存雪崩,都是找不到key了,但是穿透是mysql里也压根没有这个key
什么是缓存穿透?
一般的缓存系统,都是按照 key 去缓存查询,如果不存在对应的 value,就应该去数据库。一些恶意的请求会故意查询不存在的 key,请求量很大,就会对后端系统造成很大的压力。这就叫做缓存穿透。
如何避免?
步骤1:对可能存在结果的key,但现在查询结果为空的情况进行缓存,缓存时间设置短一点,防止后续key有了真实数据。如果要设置时间长,那么插入该 key 对应的数据之后需要注意删除对应的缓存。
步骤2:对一定不存在的 key 进行过滤。布隆过滤器。可以把所有的可能存在的 key 放到一个大的 Bitmap 中,查询时通过该 bitmap 过滤。为什么用白名单,布隆过滤器能保证正确的一定通过,不正确的大概率不通过。如果放黑名单,则有可能正常用户也无法进入。
什么是缓存雪崩?
定义:当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,会给后端系统带来很大压
力。导致系统崩溃。与缓存穿透相比,都是缓存中找不到了,但是要查询的数据真实存在数据库中,不是恶意的攻击。
考虑发生的原因,尝试避免:
不同的原因有不同适合的方案
比如单纯的超时,那么可以不同的 key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
或者做二级缓存,A1 为原始缓存,A2 为拷贝缓存,A1 失效时,可以访问 A2,A1 缓存失效时间设置
为短期,A2 设置为长期
再比如分布式缓存,如果映射算法没选好,也会导致缓存雪崩。因为一定是同时发生的,这时就不能从让缓存在不同时间失效这个思路上去考虑。
比如传统的哈希取模算法,如果添加节点,那么旧的key和存储所在的redis节点间的映射规则会被打乱,缓存需要全部失效,即 “缓存雪崩”,这将把流量全部打到数据库。解决,一致性哈希+虚拟节点。
如果还是发生了,如何补救?
在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个 key 只允许一个线程查询数据和写缓存,其他线程等待,避免重复查询。亦或者再严格点,同时只能有几个线程进行查询。
应用-排行榜
集合(Set)和有序集合(SortedSet)通过哈希表实现的。
有序集合首先是集合,其成员(member)具有唯一性,其次,每个成员关联了一个分数(score),使得成员可以按照分数排序。
ZRANGE key名 0 10 WITHSCORES #默认递增,并
zrevrange #递减
zscore 排行榜名 username#查看user2这个玩家在lb排行榜中的分数。
zincrby 排行榜名 6 username #增减玩家分数
zrem 排行榜名 username#移除(延伸:相同分数问题)
字典序排序。
如果想要按照时间,可以自己用带时间戳的分数 = 实际分数*10000000000 + (9999999999 – timestamp)。
由于32位时间戳是10位十进制整数(最大值4294967295),所以我们让时间戳占据低10位(十进制整数)。
但是仍有缺点,Redis的分数是double类型,64位双精度浮点数只有52位有效数字,它能精确表达的整数范围为-2^53到2^53,只能表示15,16位十进制整数,去掉时间只剩5,6位的分数。
应用-异步队列
List
一般使用 list 结构作为队列,rpush 生产消息,lpop 消费消息。当 lpop 没有消息的时候,要适当 sleep一会再重试或者用BLPOP阻塞式拉。
缺点,只能消费一次,lpop的时候就把它从list中删除了,而且消费者拿到数据后宕机,会消息丢失。
那能不能生产一次消费多次呢?
pub/sub 主题订阅者模式
可以实现 1:N 的消息队列。
但是除此之外都是缺点。
1.消费者下线,数据会丢失,因为找不到消费者,不会为他进行存储。
2.不支持数据持久化,不会写入到 RDB 和 AOF 中,Redis宕机,数据会丢失
3.消息堆积,缓冲区溢出,消费者会被强制踢下线,数据也会丢失
List是拉模型,pub/sub是推模型。
Stream
Redis作者在开发Redis期间,还另外开发了一个开源项目disque,是一个基于内存的分布式消息队列中间件。
在Redis5.0版本,作者把disque功能移植到了Redis中,并给它定义了一个新的数据类型:Stream。
1.Redis本身可能会丢数据
2.面对消息积压,Redis内存资源紧张
结论
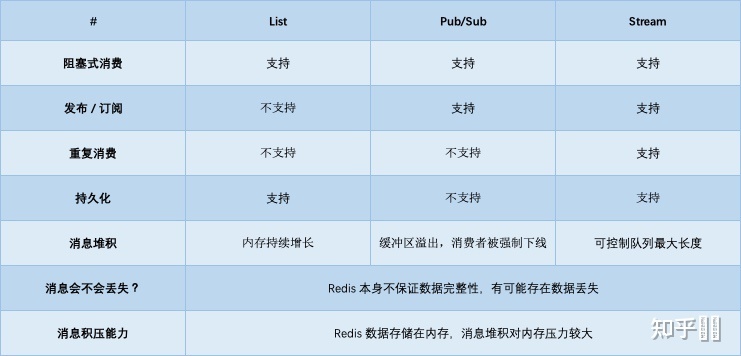
所以如果业务简单,对于数据丢失不敏感,积压概率不大的情况下,可以用redis,还很轻量。
其他情况还是得用专业的消息队列
应用-分布式锁
加锁机制
咱们来看上面那张图,现在某个客户端要加锁。如果该客户端面对的是一个 redis cluster 集群,他首先会根据 hash 节点选择一台机器。这里注意,仅仅只是选择一台机器!这点很关键!紧接着,就会发送一段 lua 脚本到 redis 上,那段 lua 脚本如下所示:为啥要用 lua 脚本呢?因为一大坨复杂的业务逻辑,可以通过封装在 lua 脚本中发送给 redis,保证这段复杂业务逻辑执行的原子性。
那么,这段 lua 脚本是什么意思呢?这里 KEYS[1]代表的是你加锁的那个 key,比如说:
RLock lock = redisson.getLock("myLock");这里你自己设置了加锁的那个锁 key 就是“myLock”。
ARGV[1]代表的就是锁 key 的默认生存时间,默认 30 秒。ARGV[2]代表的是加锁的客户端的ID,类似于下面这样:8743c9c0-0795-4907-87fd-6c719a6b4586:1
给大家解释一下,第一段 if 判断语句,就是用“exists myLock”命令判断一下,如果你要加锁的那个锁 key 不存在的话,你就进行加锁。如何加锁呢?很简单,用下面的命令:hset myLock8743c9c0-0795-4907-87fd-6c719a6b4586
通过这个命令设置一个 hash 数据结构,这行命令执行后,会出现一个类似下面的数据结构:上述就代表“8743c9c0-0795-4907-87fd-6c719a6b4586:1”这个客户端对“myLock”这个锁 key 完成了加锁。接着会执行“pexpire myLock 30000”命令,设置 myLock 这个锁 key 的生存时间是 30 秒。好了,到此为止,ok,加锁完成了。
锁互斥机制
那么在这个时候,如果客户端 2 来尝试加锁,执行了同样的一段 lua 脚本,会咋样呢?很简单,第一个 if 判断会执行“exists myLock”,发现 myLock 这个锁 key 已经存在了。接着第二个 if 判断,判断一下,myLock 锁 key 的 hash 数据结构中,是否包含客户端 2 的 ID,但是明显不是的,因为那里包含的是客户端 1 的 ID。
所以,客户端 2 会获取到 pttl myLock 返回的一个数字,这个数字代表了 myLock 这个锁 key的剩余生存时间。比如还剩 15000 毫秒的生存时间。此时客户端 2 会进入一个 while 循环,不停的尝试加锁。
watch dog自动延期机制
客户端 1 加锁的锁 key 默认生存时间才 30 秒,如果超过了 30 秒,客户端 1 还想一直持有这把锁,怎么办呢?
简单!只要客户端 1 一旦加锁成功,就会启动一个 watch dog 看门狗,他是一个后台线程,会每隔 10 秒检查一下,如果客户端 1 还持有锁 key,那么就会不断的延长锁 key 的生存时间。
可重入加锁机制
那如果客户端 1 都已经持有了这把锁了,结果可重入的加锁会怎么样呢?比如下面这种代码:
这时我们来分析一下上面那段 lua 脚本。第一个 if 判断肯定不成立,“exists myLock”会显示锁key 已经存在了。第二个 if 判断会成立,因为 myLock 的 hash 数据结构中包含的那个 ID,就是客户端 1 的那个 ID,也就是“8743c9c0-0795-4907-87fd-6c719a6b4586:1”此时就会执行可重入加锁的逻辑,他会用:incrby myLock 8743c9c0-0795-4907-87fd-6c71a6b4586:1 1 ,通过这个命令,对客户端 1的加锁次数,累加 1。此时 myLock 数据结构变为下面这样:大家看到了吧,那个 myLock 的 hash 数据结构中的那个客户端 ID,就对应着加锁的次数
释放锁机制
如果执行 lock.unlock(),就可以释放分布式锁,此时的业务逻辑也是非常简单的。其实说白了,就是每次都对 myLock 数据结构中的那个加锁次数减 1。如果发现加锁次数是 0 了,说明这个客户端已经不再持有锁了,此时就会用:“del myLock”命令,从 redis 里删除这个 key。然后呢,另外的客户端 2 就可以尝试完成加锁了。这就是所谓的分布式锁的开源 Redisson 框架的实现机制。
一般我们在生产系统中,可以用 Redisson 框架提供的这个类库来基于 redis 进行分布式锁的加锁与释放锁。
上述 Redis分布式锁的缺点
其实上面那种方案最大的问题,就是如果你对某个 redis master 实例,写入了 myLock 这种锁key 的 value,此时会异步复制给对应的 master slave 实例。但是这个过程中一旦发生 redis master 宕机,主备切换,redis slave 变为了 redis master。接着就会导致,客户端 2 来尝试加锁的时候,在新的 redis master 上完成了加锁,而客户端 1也以为自己成功加了锁。此时就会导致多个客户端对一个分布式锁完成了加锁。这时系统在业务语义上一定会出现问题,导致各种脏数据的产生。
所以这个就是 redis cluster,或者是 redis master-slave 架构的主从异步复制导致的 redis 分布式锁的最大缺陷:在 redis master 实例宕机的时候,可能导致多个客户端同时完成加锁。
(延伸)为了解决Redis单点问题,redis的作者提出了RedLock算法,但是仍有问题。不可兼顾
一般来说,用Redis控制共享资源并且还要求数据安全要求较高的话,最终的保底方案是对业务数据做幂等控制,这样一来,即使出现多个客户端获得锁的情况也不会影响数据的一致性
使用过 Redis 分布式锁么,它是怎么实现的?
先拿 setnx 来争抢锁,抢到之后,再用 expire 给锁加一个过期时间防止锁忘记了释放。
如果在 setnx 之后执行 expire 之前进程意外 crash 或者要重启维护了,那会怎么样?
用SETEX,事务,或者lua脚本可以同时把 setnx 和 expire 合成一条指令来用的!
SETNX是『 SET if Not eXists』(如果不存在,则 SET)的简写,设置成功就返回1,否则返回0。
MySQL与redis双写一致性如何保证?
分布式系统中,可以理解为多个节点中数据的值是一致的。分为强一致性,弱一致性(最终一致性)
强一致性:在任意时刻,所有节点中的数据是一样的。
最终一致性:系统会保证在一定时间内,能够达到一个数据一致的状态。
旁路缓存模式策略Cache-Aside Pattern
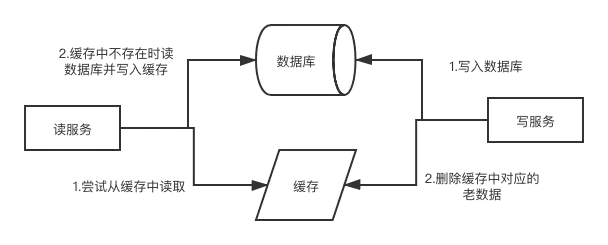
写:mysql先更新,再删除redis中对应的数据。
读:缓存读不到,从db取返回,然后再写缓存
在写数据的过程中,可以先删除 cache ,后更新 DB 么?
读写并发同一条数据时会出问题。其他读请求可能将旧数据写到缓存里,造成不一致性。
可以更新缓存吗?
更新缓存的话,在多个写服务并发的时候,如果不能保证写数据库和更新缓存的原子性(可能更新乱序,导致缓存中是先写的数据),可能造成缓存和数据库的数据不一致
先更新 DB,后删除 cache 就一定没有问题了么?
不一定,只是概率小。比如一开始没缓存,在他更新db和删除缓存的过程两端,分别进行读db,写缓存。为什么概率小,因为写缓存比数据库快的多,一般不会出现在最后。
旁路缓存的缺点:
不适合写多读少,导致cache中的数据会被频繁的删除,缓存命中率低,需要多次查询db,缓存的作用就没了。
解决办法:更新DB的时候同样更新cache
- 数据库和缓存强一致性场景:加一个锁/分布式锁来保证 写db和更新
cache是个原子操作,避免不一致的问题。 - 弱一致性:给缓存加一个比较短的过期时间,这样的话就可以保证即使数据不一致的话影响也比较小
读写穿透策略Read-Through/Write through
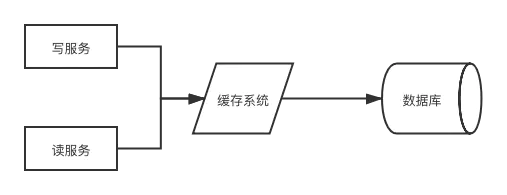
读写穿透中服务端把cache视为主要数据存储。
用得少,大概率是因为我们经常使用的分布式缓存 Redis 并没有提供 cache 将数据写入 DB 的功能。
写:
cache中存在,则先更新cache,然后cache服务自己更新DB(同时更新DB和cache)- 不存在,则直接更新db
读:多了一层封装。不直接跟db打交道。而是跟缓存服务打交道。
问缓存服务要,不管缓存里面有没有。
缓存服务怎么处理呢?读到了则直接返回,没读到则先从DB加载写入到cache后,再返回响应。
缺点
1.缓存系统会比较复杂
2.而且缓存与数据库同步实际上是业务逻辑,这就相当于业务逻辑散落在上游服务和缓存系统两个系统上,不方便维护
3.须保证缓存系统读写请求的原子性。读写并发时,从mysql读但还未写入redis,新写了一条到redis并同步到mysql,之后前面的读再写入redis,会导致缓存有段时间,是旧的。
上面两者都有的缺点:首次请求的数据一定不在cache,解决办法:可以将热点数据提前写入cache中。
异步缓存写入策略 Write behind
只更新缓存,不同步更新 DB,而是异步批量的方式来更新 DB。
非常适合一些数据经常变化又对数据一致性要求没那么高的场景,比如浏览量、点赞量。
如果真的要写多那么需要用消息队列做削峰处理,或者做集群。
常用-旁路缓存,适合读多
mysq更新时同步更新redis,保证更新成功。
mysql更新时,删除redis中对应的数据。
Elasticsearch
数据类型
Elasticsearch 有很多数据类型,大致如下:
- 基本数据类型:
- string 类型。ES 7.x 中,string 类型会升级为:text 和 keyword。keyword 可以排序;text 默认分词,不可以排序。
- 数据类型:integer、long 等
- 时间类型、布尔类型、二进制类型、区间类型等
- 复杂数据类型:
- 数组类型:Array
- 对象类型:Object
- Nested 类型
- 特定数据类型:地理位置、IP 等
注意:tring/nested/array 类型字段不能用作排序字段。因此 string 类型会升级为:text 和 keyword。keyword 可以排序,text 默认分词,不可以排序。
Object与Nested类型区别
nested是特殊的对象类型,特殊在数组的存储方式上,具体表现在允许数组中的对象各自地进行索引
es中数组是隐式的,任何一个类型如果存入时给的是这个类型的数组,则自动变为[ ]
但实际存储与直观是相反的,object类型的数组,会将各个字段合并存储。
nested则是将各个对象分开存储
构建集群,主节点
启动一个 ES 实例就是一个节点,节点加入集群是通过配置文件中设置相同的 cluste.name 而实现的。所以集群是由一个或者多个拥有相同 cluster.name 配置的节点组成, 它们共同承担数据和负载的压力。当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。
与其他组件集群(mysql,redis)的 master-slave模式一样,ES集群中也会选举一个节点成为主节点,主节点它的职责是维护全局集群状态,在节点加入或离开集群的时候重新分配分片
所有主要的文档级别API(索引,删除,搜索)都不与主节点通信,主节点并不需要涉及到文档级别的变更和搜索等操作,所以当集群只拥有一个主节点的情况下,即使流量的增加它也不会成为瓶颈。 任何节点都可以成为主节点。如果集群中就只有一个节点,那么它同时也就是主节点。
作为用户,我们可以将请求发送到 集群中的任何节点 ,包括主节点。 每个节点都知道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。
选主算法
ES7之前,Bully算法的基本原理就是,根据节点的ID大小来判定谁是leader
Bully算法在选举的时候会发送三种消息类型
- 选举消息 (Election Message: Sent to announce election.)
- 应答消息(Answer (Alive) Message: 响应选举消息)
- 选举成功消息 (Coordinator (Victory) Message:当他找不到比他更大的id了,就宣布自己成功)
ES7之后,类Raft算法。三种角色。
-
Follower 跟随者
-
Candidate 候选人
-
Leader 领导者
所有的节点都是Follower跟随者
此时此刻,如果没有收到leader的消息,那么节点将会自动转换为Candidate候选人的身份。
保证最后当选的leader为主leader
发现机制
ES目前主要推荐的自动发现机制,有如下几种:
- Azure classic discovery 插件方式,多播
- EC2 discovery 插件方式,多播
- Google Compute Engine (GCE) discovery 插件方式,多播
-
Zen discovery 默认实现,多播/单播
Zen Discovery 是 ES 默认内建发现机制。它提供单播和多播的发现方式,并且可以扩展为通过插件支持云环境和其他形式的发现。
同一台主机上配置了cluster.name即可自动加入
不同主机配置一个可连接到的单播主机列表。
单播主机列表通过discovery.zen.ping.unicast.hosts来配置。这个配置在 elasticsearch.yml 文件中:
discovery.zen.ping.unicast.hosts: ["host1", "host2:port"]具体的值是一个主机数组或逗号分隔的字符串。每个值应采用host:port或host的形式(其中port默认为设置transport.profiles.default.port,如果未设置则返回transport.tcp.port)。请注意,必须将IPv6主机置于括号内。此设置的默认值为127.0.0.1,[:: 1]。
Elasticsearch 官方推荐我们使用 单播 代替 组播。而且 Elasticsearch 默认被配置为使用 单播 发现,以防止节点无意中加入集群。只有在同一台机器上运行的节点才会自动组成集群。
单播列表不需要包含你的集群中的所有节点,它只是需要足够的节点,当一个新节点联系上其中一个并且说上话就可以了。如果你使用 master 候选节点作为单播列表,你只要列出三个就可以了。
存储与路由
已知前提:即在某种程度下,磁盘顺序I/O访问(特别是写操作)是能够匹敌内存的随机I/O访问性能的。
LSM树(Log-Structured-Merge-Tree)正如它的名字一样,LSM树会将所有的数据插入、修改、删除等操作记录(注意是操作记录)保存在内存之中,当此类操作达到一定的数据量后,再批量地顺序写入到磁盘当中。这与B+树不同,B+树数据的更新会直接在原数据所在处修改对应的值,但是LSM数的数据更新是日志式的,当一条数据更新是直接append一条更新记录完成的。因此当MemTable达到一定大小flush到持久化存储变成SSTable后,在不同的SSTable中,可能存在相同Key的记录,当然最新的那条记录才是准确的。
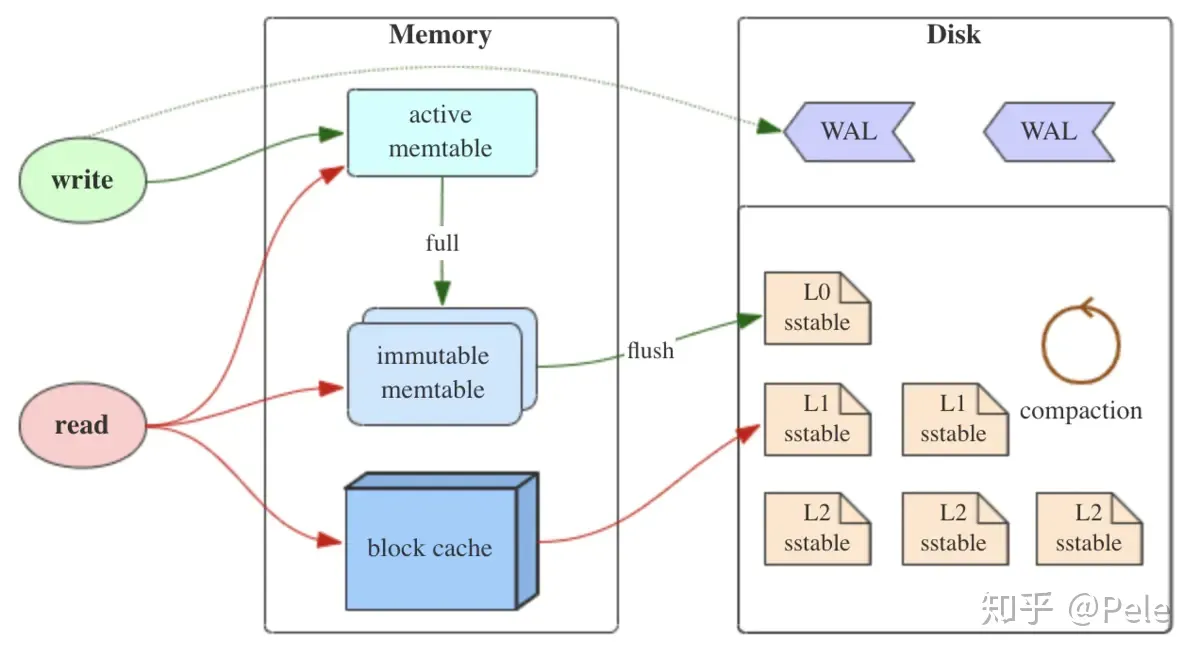
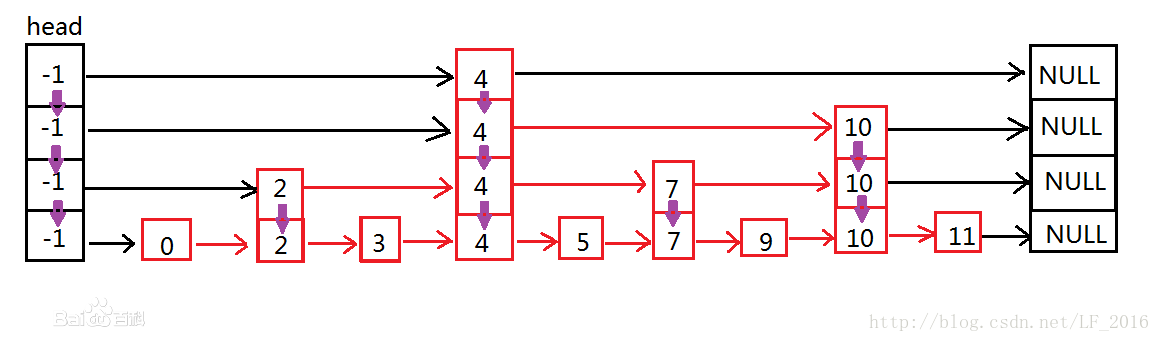
MemTable是在内存中的数据结构,用于保存最近更新的数据,会按照Key有序地组织这些数据,LSM树对于具体如何组织有序地组织数据并没有明确的数据结构定义,例如Hbase使跳跃表来保证内存中key的有序。
跳表是一个随机化的数据结构,实质就是一种可以进行二分查找的有序链表。 跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。 跳表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能。
因为数据暂时保存在内存中,内存并不是可靠存储,如果断电会丢失数据,因此通常会通过WAL(Write-ahead logging,预写式日志)的方式来保证数据的可靠性。
当 MemTable达到一定大小后,会转化成Immutable MemTable。Immutable MemTable是将转MemTable变为SSTable的一种中间状态。写操作由新的MemTable处理,在转存过程中不阻塞数据更新操作。
SSTable(Sorted String Table)有序键值对集合,是LSM树组在磁盘中的数据结构。读取时需要从最新的倒着查询,直到找到某个key的记录。最坏情况需要查询完所有的SSTable,这里可以通过前面提到的索引/布隆过滤器来优化查找速度。为了加快SSTable的读取,可以通过建立key的索引以及布隆过滤器来加快key的查找。

LSM树的Compact策略
从上面可以看出,Compact操作是十分关键的操作,否则SSTable数量会不断膨胀。在Compact策略上,主要介绍两种基本策略:size-tiered和leveled。
他们都是分层的,最大的区别在于key是否一层内唯一
stable大小是否随着层数增加而增加。
1) size-tiered(层叠) 策略
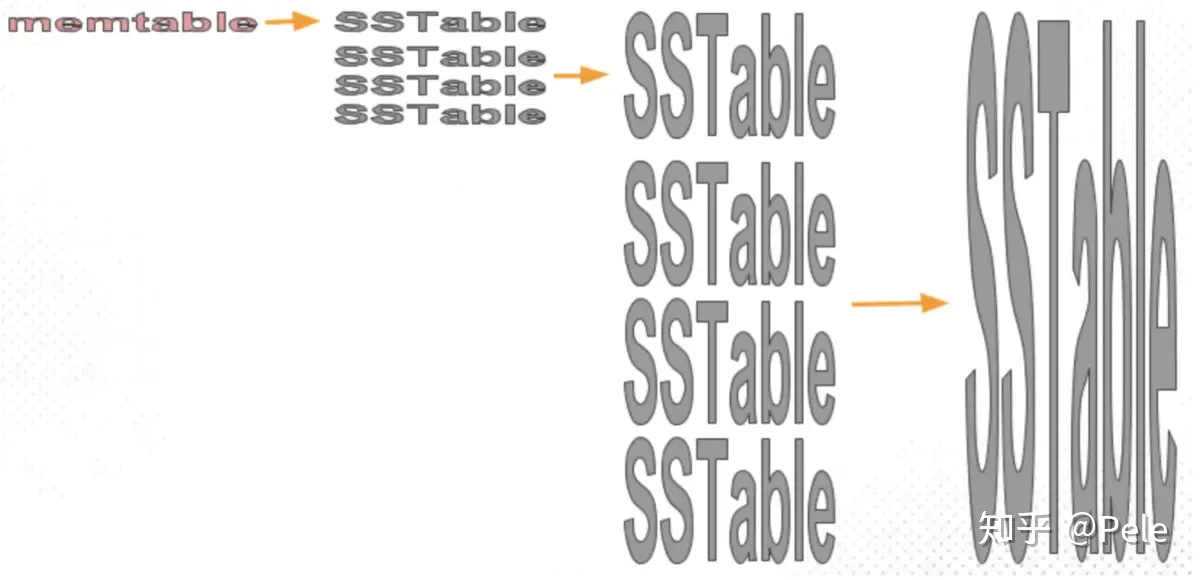
每层限制SSTable为N,当每层SSTable达到N后,则触发Compact操作合并这些SSTable,并将合并后的结果写入到下一层成为一个更大的sstable。
缺点是,当层数达到一定数量时,最底层的单个SSTable的大小会变得非常大。并且size-tiered策略会导致空间放大比较严重。即使对于同一层的SSTable,每个key的记录是可能存在多份的,只有当该层的SSTable执行compact操作才会消除这些key的冗余记录。
2) leveled策略
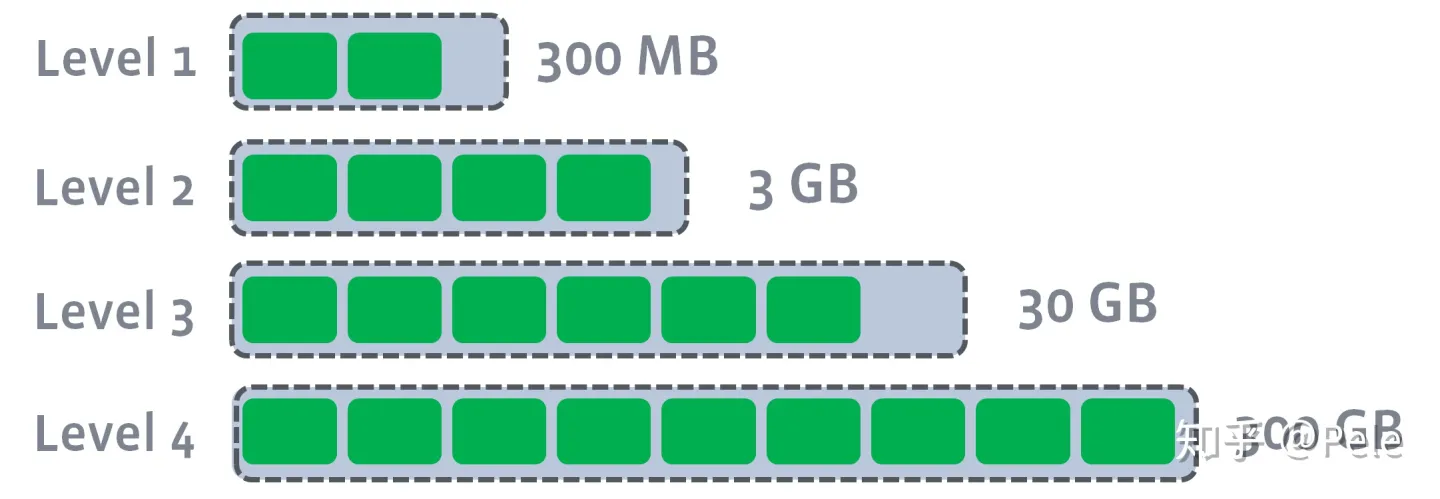
每一层限制总文件的大小,从上到下逐渐变大
每层都有大小相近的SSTable。这些SSTable是这一层是全局有序的,意味着一个key在每一层至多只有1条记录,不存在冗余记录。
因此空间放大问题得到缓解。但是写放大问题会更加突出。举一个最坏场景,如果LevelN层某个SSTable的key的范围跨度非常大,覆盖了LevelN+1层所有key的范围,那么进行Compact时将涉及LevelN+1层的全部数据。
如何合并?此时会从L1中选择至少一个文件,然后把它跟L2有交集的部分(非常关键)进行合并。生成的文件会放在L2。
索引在默认情况下会被分配5个主分片和每个主分片的1个副本
实际上,这个主分片数目定义了这个索引能够 存储 的最大数据量。
shard = hash(routing) % number_of_primary_shardsrouting 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。 routing 通过 hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到 余数 。这个分布在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。
这就解释了为什么我们要在创建索引的时候就确定好主分片的数量 并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
在创建索引的时候合理的预分配分片数是很重要的。
LSM-Tree VS B+ Teee
下面给出两者的对比
| 区别 | LSM-Tree | B+ Teee |
|---|---|---|
| 应用场景 | K-V数据库、日志数据库(频繁写) | 关系型数据库(频繁读) |
| 写入性能 | 批量顺序写,且采用追加写(不需更新),写入性能高 | 单条随机写入,且索引需要更新,写入性能低 |
| 查找性能 | 存在读放大,查询性能低O(N),经过索引、缓存优化后可以O(LogN) | 查找性能极高,O(LogN) |
| 删除与修改 | 追加写入,标记删除,在compaction阶段才能真正删除 | 原地更新与删除 |
| 存储方式 | 内存+硬盘 | 硬盘 |
主分片和副本分片如何交互
我们可以发送请求到集群中的任一节点。每个节点都有能力处理任意请求。每个节点都知道集群中任一文档位置,所以可以直接将请求转发到需要的节点上。 在下面的例子中,将所有的请求发送到 Node 1 ,我们将其称为 协调节点(coordinating node)。
当发送请求的时候,为了扩展负载,更好的做法是轮询集群中所有的节点。
以下是在主副分片和任何副本分片上面 成功新建,索引和删除文档所需要的步骤顺序:
- 客户端向 Node 1 发送新建、索引或者删除请求。
- 节点使用文档的 _id 确定文档属于分片 0 。请求会被转发到 Node 3,因为分片 0 的主分片目前被分配在 Node 3 上。
- Node 3 在主分片上面执行请求。如果成功了,它将请求并行转发到 Node1 和 Node2 的副本分片上。一旦所有的副本分片都报告成功,Node 3 将向协调节点报告成功,协调节点向客户端报告成功。
在客户端收到成功响应时,文档变更已经在主分片和所有副本分片执行完成,变更是安全的。
在处理读取请求时,协调结点在每次请求的时候都会通过轮询所有的副本分片来达到负载均衡。
处理并发冲突-内部版本号,外部版本号
在数据库领域中,有两种方法通常被用来确保并发更新时变更不会丢失:
- 悲观锁
这种方法被关系型数据库广泛使用,它假定有变更冲突可能发生,因此阻塞访问资源以防止冲突。 一个典型的例子是读取一行数据之前先将其锁住,确保只有放置锁的线程能够对这行数据进行修改。 - 乐观锁CAS
Elasticsearch 中使用的这种方法假定冲突是不可能发生的,并且不会阻塞正在尝试的操作。然而,如果源数据在读写当中被修改,更新将会失败。应用程序接下来将决定该如何解决冲突。例如,可以重试更新、使用新的数据、或者将相关情况报告给用户。
Elasticsearch 中对文档的 index , GET 和 delete 请求时,我们指出每个文档都有一个 _version (版本)号,当文档被修改时版本号递增。
Elasticsearch 使用这个 _version 号来确保变更以正确顺序得到执行。如果旧版本的文档在新版本之后到达,它可以被简单的忽略。
所有文档的更新或删除 API,都可以接受 version 参数,这允许你在代码中使用乐观的并发控制。
默认的_version是es自动生成的。
我们也可以自己外部指定。使用其它数据库作为主要的数据存储,使用 Elasticsearch 做数据检索, 这意味着主数据库的所有更改发生时都需要被复制到 Elasticsearch ,如果多个进程负责这一数据同步,可能遇到并发问题。
如果你的主数据库已经有了版本号,或一个能作为版本号的字段值比如 timestamp,那么你就可以在 Elasticsearch 中通过增加 version_type=external到查询字符串的方式重用这些相同的版本号,版本号必须是大于零的整数, 且小于 9.2E+18(一个 Java 中 long 类型的正值)。
外部版本号的处理方式和我们之前讨论的内部版本号的处理方式有些不同, Elasticsearch 不是检查当前 _version 和请求中指定的版本号是否相同,而是检查当前_version 是否小于指定的版本号。如果请求成功,外部的版本号作为文档的新_version 进行存储。
外部版本号不仅在索引和删除请求是可以指定,而且在创建新文档时也可以指定。
例如,要创建一个新的具有外部版本号 5 的博客文章,我们可以按以下方法进行:
PUT /website/blog/2?version=5&version_type=external
{
"title": "My first external blog entry",
"text": "Starting to get the hang of this..."
}在响应中,我们能看到当前的 _version 版本号是 5 :
{
"_index": "website",
"_type": "blog",
"_id": "2",
"_version": 5,
"created": true
}现在我们更新这个文档,指定一个新的 version 号是 10 :
PUT /website/blog/2?version=10&version_type=external
{
"title": "My first external blog entry",
"text": "This is a piece of cake..."
}请求成功并将当前 _version 设为 10 :
{
"_index": "website",
"_type": "blog",
"_id": "2",
"_version": 10,
"created": false
}如果你要重新运行此请求时,它将会失败,并返回像我们之前看到的同样的冲突错误,因为指定的外部版本号不大于 Elasticsearch 的当前版本号。
Mongodb
nosql中的文档数据库
存储官网文档写B树,实际上B+树。
B+树对于范围查询更好,因为叶子结点之间有指针。
使用时:mysql可能不同数据放在不同表里,如班级学生放两个表里,而文档数据库可以一个json格式,将学生放在班级里。
| 比较项 | MongoDB | ElasticSearch | 备注 |
|---|---|---|---|
| 定位 | (文档型)数据库 | (文档型)搜索引擎 | 一个管理数据,一个检索数据 |
| 资源占用 | 一般 | 高 | mongo使用c++, es使用Java开发 |
| 写入延迟 | 低 | 高 | es的写入延迟默认1s, 可配置, 但是要牺牲一些东西 |
| 全文索引支持度 | 一般 | 非常好 | es本来就是搜索引擎, 这个没啥可比性 |
| 有无Schema | 无 | 无 | 两者都是无Schema |
| 支持的数据量 | PB+ | TB+ ~ PB | 两者支持的量并不好说的太死, 都支持分片和横向扩展, 但是相对来说MongoDB的数据量支持要更大一点 |
| 性能 | 非常好 | 好 | MongoDB在大部分场景性能比es强的多 |
| 索引结构 | B树 | LSM树 | es追求写入吞吐量, MongoDB读写比较均衡 |
| 操作接口 | TCP | Restful(Http) | |
| 是否支持分片 | 是 | 是 | |
| 是否支持副本 | 是 | 是 | |
| 选主算法 | Bully(霸凌) | Bully(霸凌) | 相比于Paxos和Raft算法实现更简单并有一定可靠性上的妥协,但是选举速度比较快 |
| 扩展难度 | 容易 | 非常容易 | es真的是我用过的扩展最方便的存储系统之一 |
| 配置难度 | 难 | 非常容易 | |
| 地理位置 | 支持 | 支持 | |
| 运维工具 | 丰富 | 一般 | |
| 插件和引擎 | 有多个存储引擎供选择 | 有大量插件可以使用 |
- MongoDB适合
- 对服务可用性和一致性有高要求
- 无schema的数据存储 + 需要索引数据
- 高读写性能要求, 数据使用场景简单的海量数据场景
- 有热点数据, 有数据分片需求的数据存储
- 日志, html, 爬虫数据等半结构化或图片,视频等非结构化数据的存储
- 有js使用经验的人员(MongoDB内置操作语言为js)
- Elasticsearch适合
- 已经有其他系统负责数据管理
- 对复杂场景下的查询需求,对查询性能有要求, 对写入及时性要求不高的场景
- 监控信息/日志信息检索
- 小团队但是有多语言服务,es拥有restful接口,用起来最方便
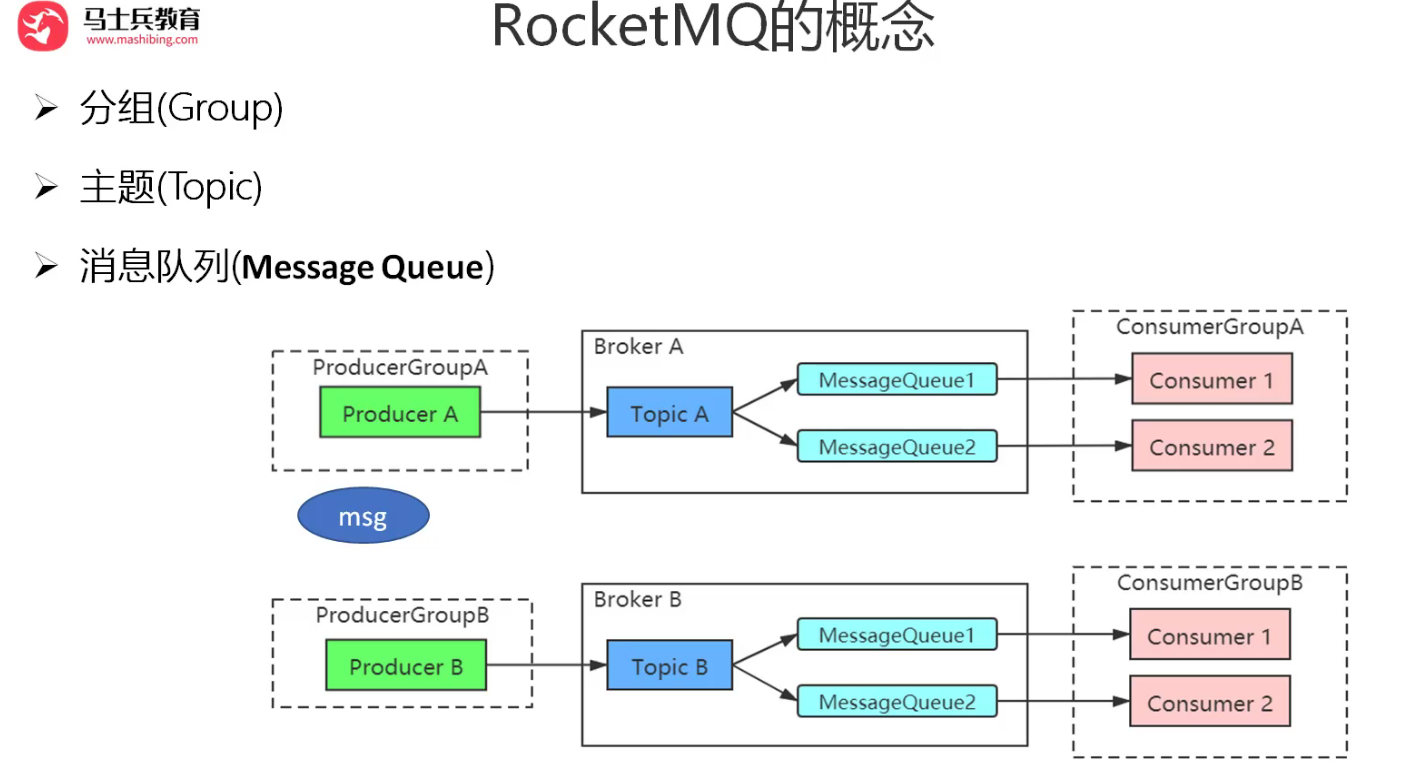
RocketMQ
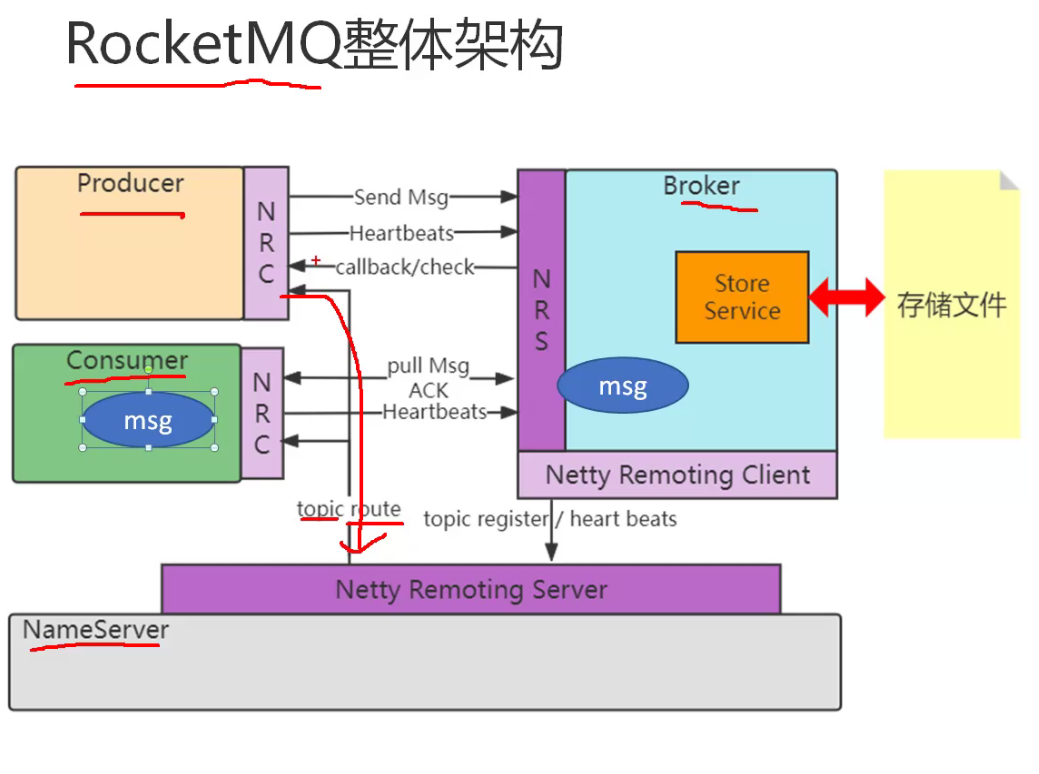

存储结构
RocketMQ消息的存储是由CommitLog和ConsumeQueue配合完成 的,消息真正的物理存储文件是CommitLog,ConsumeQueue是消息的逻辑队列,类似数据库的索引文件,存储的是指向物理存储的地址。每 个Topic下的每个Message Queue都有一个对应的ConsumeQueue文件。
存储文件设计改进
单文件,相对于kafka一个主题一个文件,超过100个,性能下降一个数量级。
提高文件读写性能的零拷贝技术
是一类技术。mmap,sendfile
200MB 2ms 200ms?mmp多少?
map方法
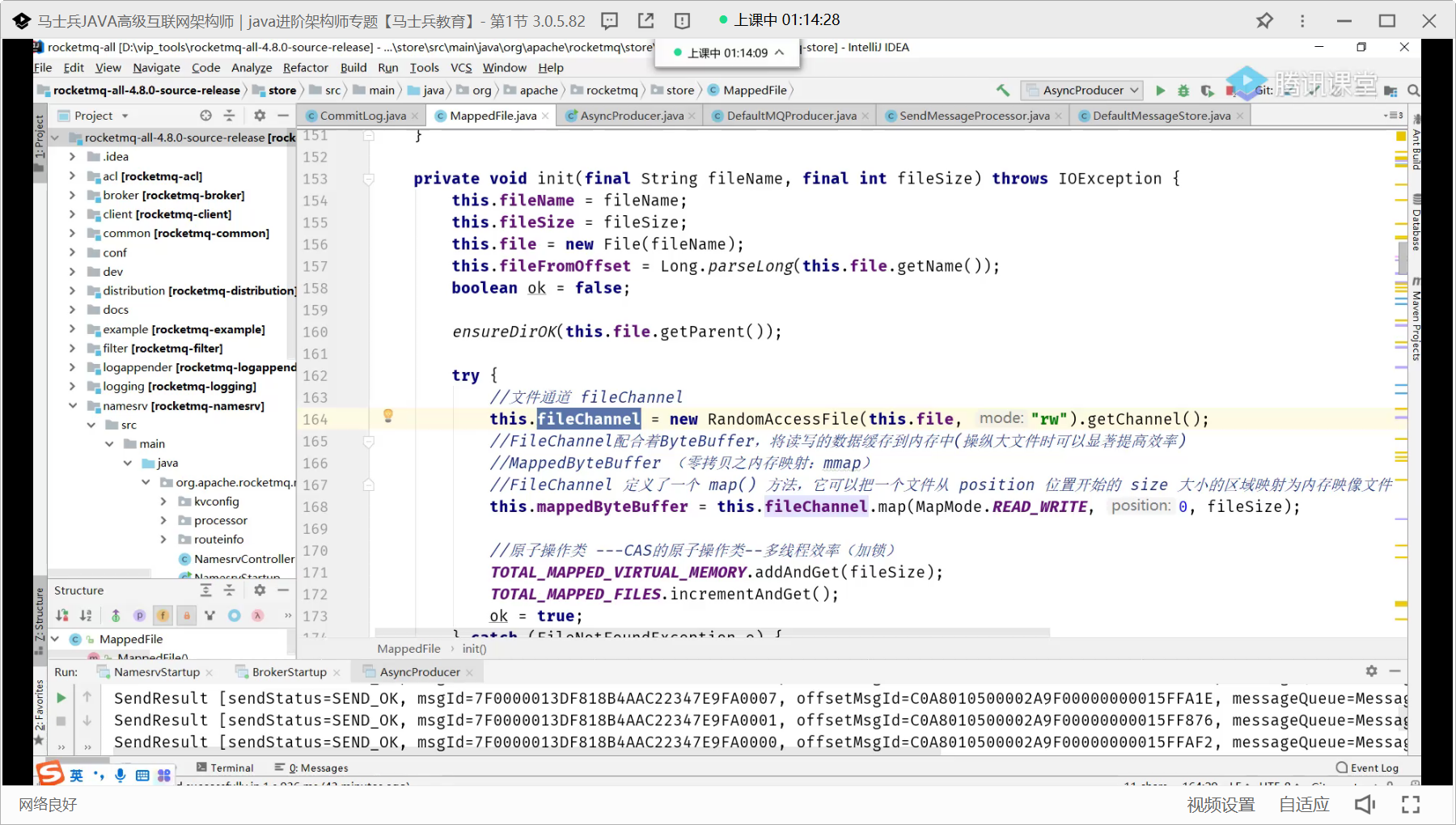
堆外内存缓冲
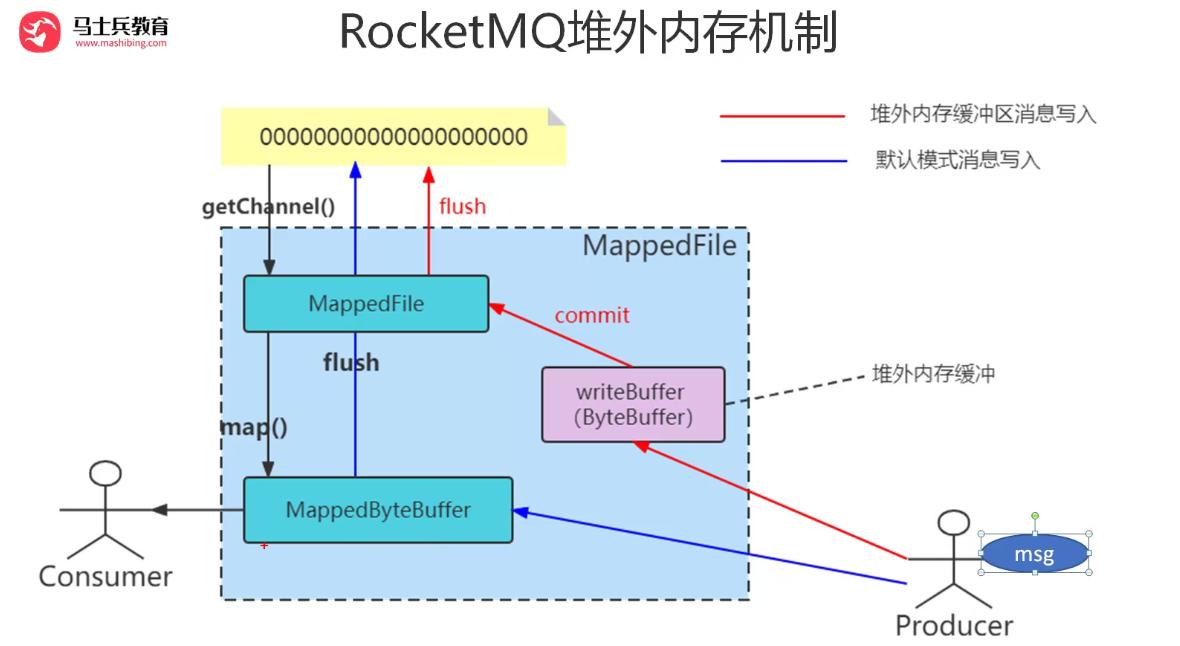
jvm不会去回收,读写分离
单文件读会加锁

堆外内存池
completableFuture返回值类型
4.7版本之后,调用线程不会阻塞,新开被调用线程执行。当异步任务完成或者发生异常时,自动调用回调对象的回调方法。
CompletableFuture可以指定异步处理流程:
thenAccept()处理正常结果;exceptional()处理异常结果;thenApplyAsync()用于串行化另一个CompletableFuture;anyOf()和allOf()用于并行化多个CompletableFuture。
提升同步双写性能
锁优化

ReentrantLock
如何保证数据不丢失
发送阶段:同步调用
存储:同步刷盘
消费:ack确认
如何顺序
写入时顺序,放到一个分区里。
Zookeeper
https://zhuanlan.zhihu.com/p/45728390 zookeeper简介
https://www.jianshu.com/p/4ba74ea57abf zookeeper如何保持一致性
https://blog.51cto.com/liangchaoxi/4049974 分布式一致性算法
满足CP
cap的这三个需求,最多只能同时满足其中的两项,因为P是必须的,因此往往选择就在CP或者AP中。
在此ZooKeeper保证的是CP
分析:可用性(A:Available)
不能保证每次服务请求的可用性。任何时刻对ZooKeeper的访问请求能得到一致的数据结果,同时系统对网络分割具备容错性;但是它不能保证每次服务请求的可用性(注:也就是在极端环境下,ZooKeeper可能会丢弃一些请求,消费者程序需要重新请求才能获得结果)。所以说,ZooKeeper不能保证服务可用性。
进行leader选举时集群都是不可用。在使用ZooKeeper获取服务列表时,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30 ~ 120s, 且选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪,虽然服务能够最终恢复,但是漫长的选举时间导致的注册长期不可用是不能容忍的。所以说,ZooKeeper不能保证服务可用性。
原理-Zab协议保证一致性
Zxid 是 Zab 协议的一个事务编号,Zxid 是一个 64 位的数字,其中低 32 位是一个简单的单调递增计数器,针对客户端每一个事务请求,计数器加 1;而高 32 位则代表 Leader 周期年代的编号。
Zab 的具体流程可以拆分为消息广播、崩溃恢复和数据同步三个过程,下面我们分别进行分析。
消息广播
在 ZooKeeper 中所有的事务请求都由 Leader 节点来处理,其他服务器为 Follower,Leader 将客户端的事务请求转换为事务 Proposal,并且将 Proposal 分发给集群中其他所有的 Follower。
完成广播之后,Leader 等待 Follwer 反馈,当有过半数的 Follower 反馈信息后,Leader 将再次向集群内 Follower 广播 Commit 信息,Commit 信息就是确认将之前的 Proposal 提交。
这里的 Commit 可以对比 SQL 中的 COMMIT 操作来理解,MySQL 默认操作模式是 autocommit 自动提交模式,如果你显式地开始一个事务,在每次变更之后都要通过 COMMIT 语句来确认,将更改提交到数据库中。
Leader 节点的写入也是一个两步操作,第一步是广播事务操作,第二步是广播提交操作,其中 过半数指的是反馈的节点数 >=N/2+1,N 是全部的 Follower 节点数量。
消息广播的过程描述可以参考下图:
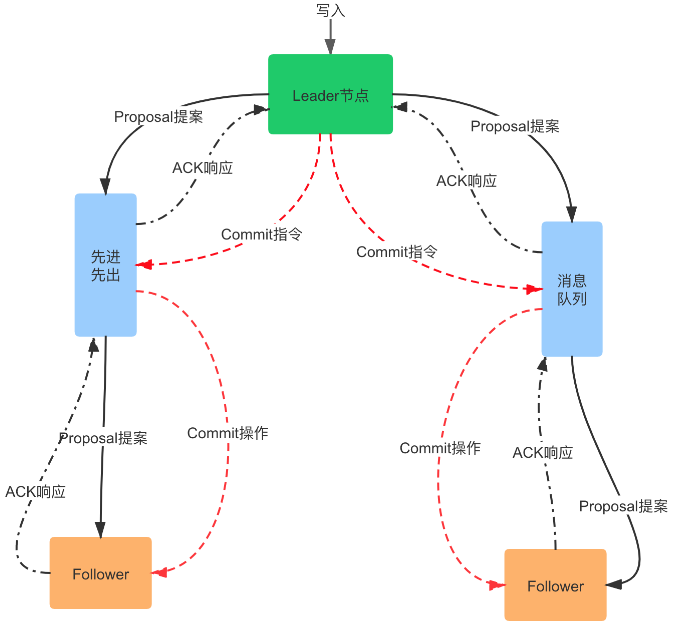
- 客户端的写请求进来之后,Leader 会将写请求包装成 Proposal 事务,并添加一个递增事务 ID,也就是 Zxid,Zxid 是单调递增的,以保证每个消息的先后顺序;
- 广播这个 Proposal 事务,Leader 节点和 Follower 节点是解耦的,通信都会经过一个先进先出的消息队列,Leader 会为每一个 Follower 服务器分配一个单独的 FIFO 队列,然后把 Proposal 放到队列中;
- Follower 节点收到对应的 Proposal 之后会把它持久到磁盘上,当完全写入之后,发一个 ACK 给 Leader;
- 当 Leader 收到超过半数 Follower 机器的 ack 之后,会提交本地机器上的事务,同时开始广播 commit, Follower 收到 commit 之后,完成各自的事务提交。
崩溃恢复
消息广播通过 Quorum 机制,解决了 Follower 节点宕机的情况,但是如果在广播过程中 Leader 节点崩溃呢?
这就需要 Zab 协议支持的崩溃恢复,崩溃恢复可以保证在 Leader 进程崩溃的时候可以重新选出 Leader,并且保证数据的完整性。
崩溃恢复和集群启动时的选举过程是一致的,也就是说,下面的几种情况都会进入崩溃恢复阶段:
- 初始化集群,刚刚启动的时候
- Leader 崩溃,因为故障宕机
- Leader 失去了半数的机器支持,与集群中超过一半的节点断连
崩溃恢复模式将会开启新的一轮选举。
选举过程如下:
1.各个节点变更状态,变更为 Looking
- ZooKeeper 中除了 Leader 和 Follower,还有 Observer 节点,Observer 不参与选举, Leader 挂后,余下的 Follower 节点都会将自己的状态变更为 Looking,然后开始进入 Leader 选举过程。
2.各个 Server 节点都会发出一个投票,参与选举
- 在第一次投票中,所有的 Server 都会投自己,然后各自将投票发送给集群中所有机器,在运行期间,每个服务器上的 Zxid 大概率不同。
3.集群接收来自各个服务器的投票,开始处理投票和选举
- 处理投票的过程就是对比 Zxid 的过程,假定 Server3 的 Zxid 最大,Server1判断Server3可以成为 Leader,那么Server1就投票给Server3,判断的依据如下:首先选举 epoch 最大的,如果 epoch 相等,则选 zxid 最大的,若 epoch 和 zxid 都相等,则选择 server id 最大的,就是配置 zoo.cfg 中的 myid;在选举过程中,如果有节点获得超过半数的投票数,则会成为 Leader 节点,反之则重新投票选举。
数据同步
选举产生的 Leader 会与过半的 Follower 进行同步,利用 Leader 前一阶段获得的最新Proposal历史,同步集群中所有的副本。使数据一致,当与过半的机器同步完成后,就退出恢复模式, 然后进入消息广播模式。
Zab 中的节点有三种状态,伴随着的 Zab 不同阶段的转换,节点状态也在变化:
分布式存储
加权轮询算法使用场景是建立在每个节点存储的数据都是相同的前提。所以,每次读数据的请求,访问任意一个节点都能得到结果。
但是,加权轮询算法是无法应对「分布式系统」的,因为分布式系统中,每个节点存储的数据是不同的。
当我们想提高系统的容量,就会将数据水平切分到不同的节点来存储,也就是将数据分布到了不同的节点。比如一个分布式 KV(key-valu) 缓存系统,某个 key 应该到哪个或者哪些节点上获得,应该是确定的,不是说任意访问一个节点都可以得到缓存结果的。
如何分配数据?
有两个目标
-
均匀性(Uniformity) :不同存储节点的负载应该均衡;
-
稳定性(Consistency):存储节点发生变化时,key通过分配算法得到的分布结果(如在那台机器上)应该保持基本稳定,即减少数据在节点间移动。
两个目标是有一定矛盾的,追求极致均匀会导致较多的数据迁移。
1.哈希方式
对节点数量取模分配,在key足够分散的情况下,均匀性很强,但稳定性无从谈起,一旦节点数量发生变化则需要全部重新计算。
2.改进,一致性哈希
在移除或者添加一个服务器时,能够尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系。
哈希环,对象和服务器ip计算hash放在环上,对象顺时针寻找下一个最近的服务器。
一致性哈希算法并不保证节点能够在哈希环上分布均匀,会出现大量请求都集中在一个节点的情况,在这种情况下进行容灾与扩容时,容易出现雪崩的连锁反应。
3.再改进
怎么解决呢,一种方法是,放大量的节点,但往往我们没有那么多节点,于是放虚拟节点,增加一层中间层,把虚拟节点放在环上,而虚拟节点和实际服务器的关系可以再指定
锁
一致性问题
ACID原理
即关系型数据库的事务特性:原子性、一致性、隔离性和持久性。ACID这里不多说,一般核心交易系统都要有强一致性的事务要求,因此在做技术选型时,核心数据基本也只考虑关系型数据库。
CAP原理
CAP(Consistency、Availablity和Partition-tolerance)其实是一种权衡平衡的思想,用于指导在系统可用性设计、数据一致性设计时做权衡取舍。CAP,即一致性、可用性、分区容忍性。
我的理解是,强一致性,可用性,分区容忍性,只能取二。
mysql单机做到了强一致性,可用性。
一致性,强调在同一时刻副本一致,能读到之前完成的写操作。一般指的是强一致性。
可用性,指的是服务在确定的的时间内完成处理并响应,
分区容忍性,说的是分布式系统本身多个节点的特点,部分节点不可用时,剩下的仍可以独立运行并提供服务。
BASE的基本含义是基本可用(Basically Availble)、软状态(Softstate)和最终一致性(Eventual consistency):
分布式事务
涉及到一个服务多个数据库的事务
或者多个服务一个数据库。?

解决
seta
引入第三方记录,称为事务管理器。
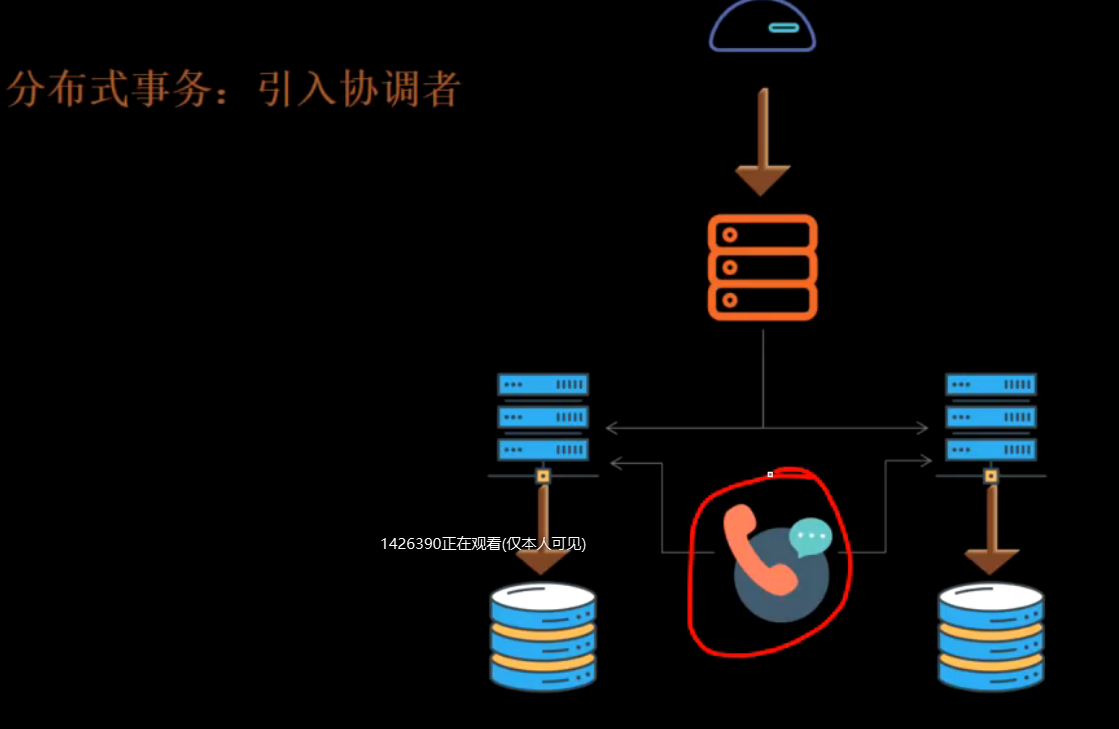
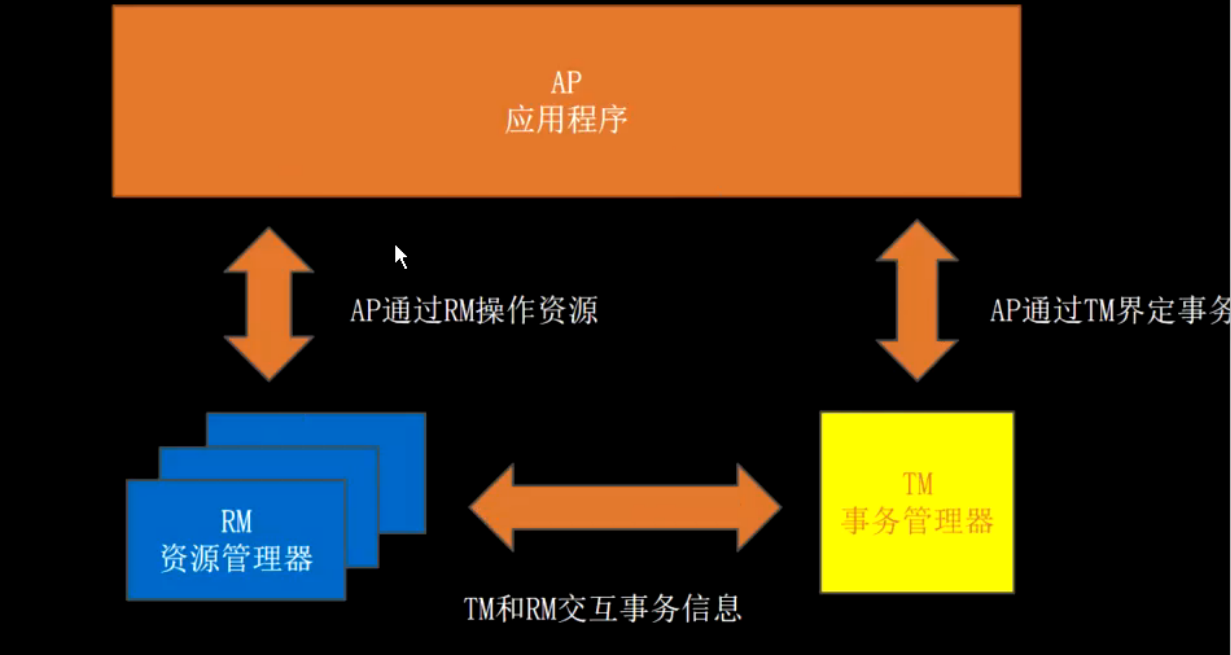
xa规范。xa接口函数由不同数据库厂商实现。XA 协议是由X/Open 组织提出的分布式事务处理规范,主要定义了事务管理器TM 和局部资源管理器RM 之间的接口。 目前主流的数据库,比如oracle、DB2 都是支持XA 协议的。
两阶段提交
第一阶段,牧师询问两方都没问题
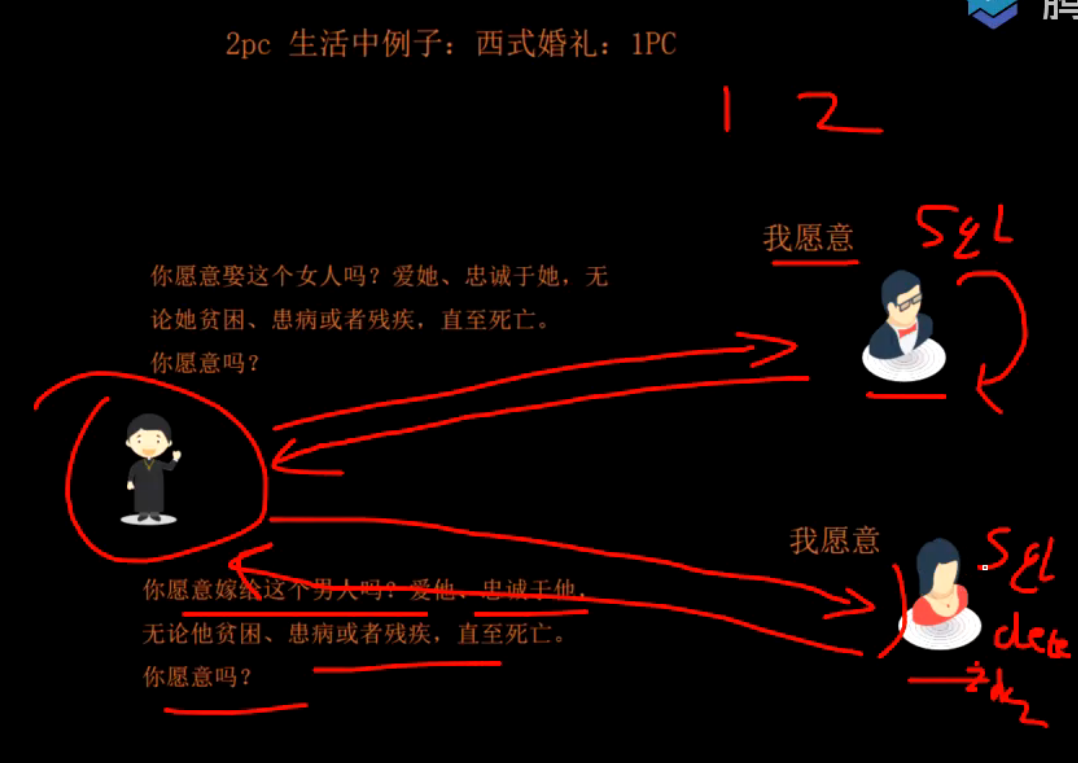
第二阶段
失败则rollback
根据本地日志回滚。
前滚回滚?
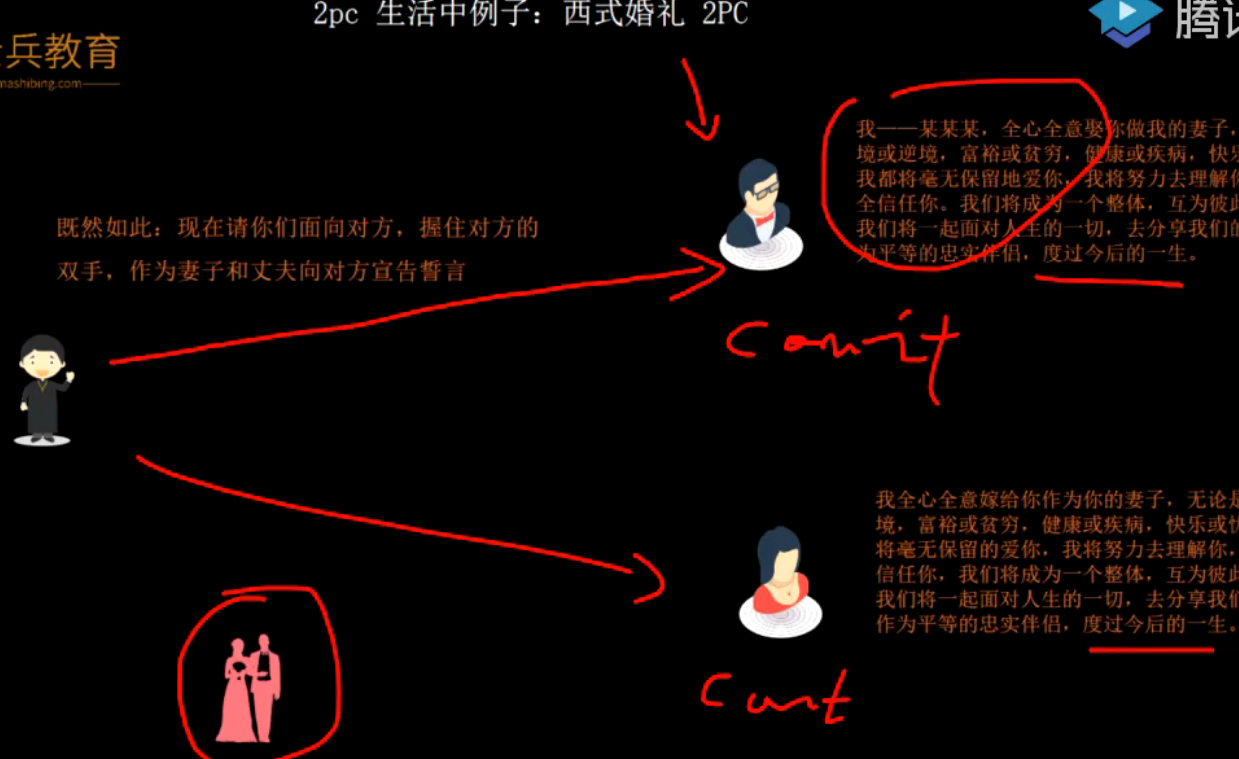
缺点

单点故障:给协调者做集群
阻塞资源:第一阶段建立的连接需要第二阶段提交后才能释放。因此不保持连接
数据不一致:如新郎挂了,或者commit没收到。概率很低,用脚本补偿。鸵鸟理论。
目前主要是用二阶段提交的。
tcc(try confirm cancel)
要么confirm要么cancel,cancel是做一下逆操作。
TCC和2PC看起来很像,TCC和2PC最大的区别是,2PC是偏数据库层面的,而TCC是纯业务层面。
TCC 事务机制相对于传统事务机制(X/Open XA),TCC 事务机制相比于上面介绍的 XA 事务机制,有以下优点:
- 性能提升:具体业务来实现控制资源锁的粒度变小,不会锁定整个资源。
- 数据最终一致性:基于 Confirm 和 Cancel 的幂等性,保证事务最终完成确认或者取消,保证数据的一致性。
- 可靠性:解决了 XA 协议的协调者单点故障问题,由主业务方发起并控制整个业务活动,业务活动管理器也变成多点,引入集群。
- 支持度:该模式对有无本地事务控制都可以支持使用面广。
缺点:TCC 的 Try、Confirm 和 Cancel 操作功能要按具体业务来实现,业务耦合度较高,提高了开发成本。
空回滚
如果协调者的Try()请求因为网络超时失败,那么协调者在阶段二时会发送Cancel()请求,而这时这个事务参与者实际上之前并没有执行Try()操作而直接收到了Cancel()请求。
针对这个问题,TCC模式要求在这种情况下Cancel()能直接返回成功,也就是要允许「空回滚」。
防悬挂
接着上面的问题1,Try()请求超时,事务参与者收到Cancel()请求而执行了空回滚,但就在这之后网络恢复正常,事务参与者又收到了这个Try()请求,所以Try()和Cancel()发生了悬挂,也就是先执行了Cancel()后又执行了Try()
针对这个问题,TCC模式要求在这种情况下,事务参与者要记录下Cancel()的事务ID,当发现Try()的事务ID已经被回滚,则直接忽略掉该请求。
幂等性
Confirm()和Cancel()的实现必须是幂等的。当这两个操作执行失败时协调者都会发起重试。
2pc与tcc区别
2pc是数据库厂商对于事务做的升级,支持分布式事务。我们可以直接用2pc来做。
tcc则是我们自己针对自己业务,自行做的一些措施来实现分布式事务,无需数据库支持。
三阶段提交
优点:相对于2PC。3PC主要解决单点故障问题,并减少阻塞,因为一旦参与者无法及时收到来自协调者的信息之后,他会默认执行commit。而不会一直持有事务资源并处于阻塞状态。
缺点:但是这种机制也会导致数据一致性问题,如由于网络原因,协调者发送的abort响应没有及时被参与者接收到,那么参与者在等待超时之后执行了commit操作。这样就和其他接到abort命令并执行回滚的参与者之间存在数据不一致的情况。
can commit 先询问是否能做,而不是直接修改。最重要的一点。节省了资源。参与者不会超时

pre commit 写redo,undo进行实际操作
do commit 提交

全局唯一id
涉及到分库分表,就会引申出分布式系统中唯一主键ID的生成问题,因为在单表中我们可以用数据库主键来做唯一ID,但是如果做了分库分表,多张单表中的自增主键就一定会发生冲突。那就不具备全局唯一性了。
那么,如何生成一个全局唯一的ID呢?有以下几种方式:
UUID
很多人对UUID都不陌生,它是可以做到全局唯一的,而且生成方式也简单,但是我们通常不推荐使用他做唯一ID,首先UUID太长了,其次字符串的查询效率也比较慢,而且没有业务含义,根本看不懂。
基于某个单表做自增主键
多张单表生成的自增主键会冲突,但是如果所有的表中的主键都从同一张表生成是不是就可以了。
所有的表在需要主键的时候,都到这张表中获取一个自增的ID。
这样做是可以做到唯一,也能实现自增,但是问题是这个单表就变成整个系统的瓶颈,而且也存在单点问题,一旦他挂了,那整个数据库就都无法写入了。
基于多个单表+步长做自增主键
为了解决单个数据库做自曾主键的瓶颈及单点故障问题,我们可以引入多个表来一起生成就行了。
但是如何保证多张表里面生成的Id不重复呢?如果我们能实现以下的生成方式就行了:
实例1生成的ID从1000开始,到1999结束。
实例2生成的ID从2000开始,到2999结束。
实例3生成的ID从3000开始,到3999结束。
实例4生成的ID从4000开始,到4999结束。
这样就能避免ID重复了,那如果第一个实例的ID已经用到1999了怎么办?那就生成一个新的起始值:
实例1生成的ID从5000开始,到5999结束。
实例2生成的ID从6000开始,到6999结束。
实例3生成的ID从7000开始,到7999结束。
实例4生成的ID从8000开始,到8999结束。
我们把步长设置为1000,确保每一个单表中的主键起始值都不一样,并且比当前的最大值相差1000就行了。
雪花算法
雪花算法也是比较常用的一种分布式ID的生成方式,它具有全局唯一、递增、高可用的特点。
雪花算法生成的主键主要由 4 部分组成,1bit符号位、41bit时间戳位、10bit工作进程位以及 12bit 序列号位。
时间戳占用41bit,精确到毫秒,总共可以容纳约69年的时间。
工作进程位占用10bit,其中高位5bit是数据中心ID,低位5bit是工作节点ID,做多可以容纳1024个节点。
序列号占用12bit,每个节点每毫秒0开始不断累加,最多可以累加到4095,一共可以产生4096个ID。
所以,一个雪花算法可以在同一毫秒内最多可以生成1024 X 4096 = 4194304个唯一的ID
分布式锁
问题产生
jmeter压测
jvm锁
解决方案-第三方,分布式锁
mysql行锁。如quartz。
redis单点锁
死锁 设置超时时间
setnx key value ex 10s
del
设置多久合适?
lua脚本,保证原子性
看门狗
Redis单点故障
一主二从三哨兵
redis红锁
投票,奇数个独立Redis,以最保守的时间为准
问题,挂了一台没有加锁的怎么办,当他还是启动的。
问题,已加锁的节点挂了,重新启动如果没了数据,则会产生问题,导致新的加锁成功。 解决,不要立刻重启,部署手册中写,延迟启动6h,等已加锁的释放
Redis stw时
JVM 中 STW 导致 Redis 锁释放怎么办
STW 过程中 “看门狗”(即守护线程)不去续期,导致锁失效。此时别的线程拿到锁,同时操作产生问题
鸵鸟策略,不考虑这种情况,因为出现的概率极低
使用 ZooKeeper + MySQL 乐观锁 ZK key 的序号做 MySQL 的 version 字段